
Postgres-XL Scalability for Loading Data
In my last blog, we looked at the benchmark results from bulk load test for a Postgres-XL database cluster. Using a 16-datanode, 2-coordinator cluster, running on EC2 instances, we could easily clock 9M rows/sec or 3TB/hr of ingestion rate. That’s a significant number in itself. In this blog, we’ll see if the ingestion rate is scalable in Postgres-XL. In particular, we’ll try to answer if adding more nodes to the cluster can result in a linear increase in performance.
Let’s use the same line item table from the TPC-H benchmark for these tests. We’ll increase the cluster size from 16 datanodes to 20 datanodes and then further to 24 datanodes. We’ll also repeat the tests with 1, 2 and 3 coordinators respectively. For all these tests, we are using i2.xlarge EC2 instance for a datanode and c3.8xlarge EC2 instance for a coordinator. Also, we are keeping the number of concurrent COPY processes to 24 for all these tests.
Sustained Bulk-load Rate
To measure if the bulk-load rate can be sustained over longer period of time and when the data significantly overflows the combined RAM on all machines, let’s measure time to load 3 billion, 6 billion and 9 billion rows on a 16-datanode cluster. The following chart shows the data load time and a steady ingestion rate even for a very large table.
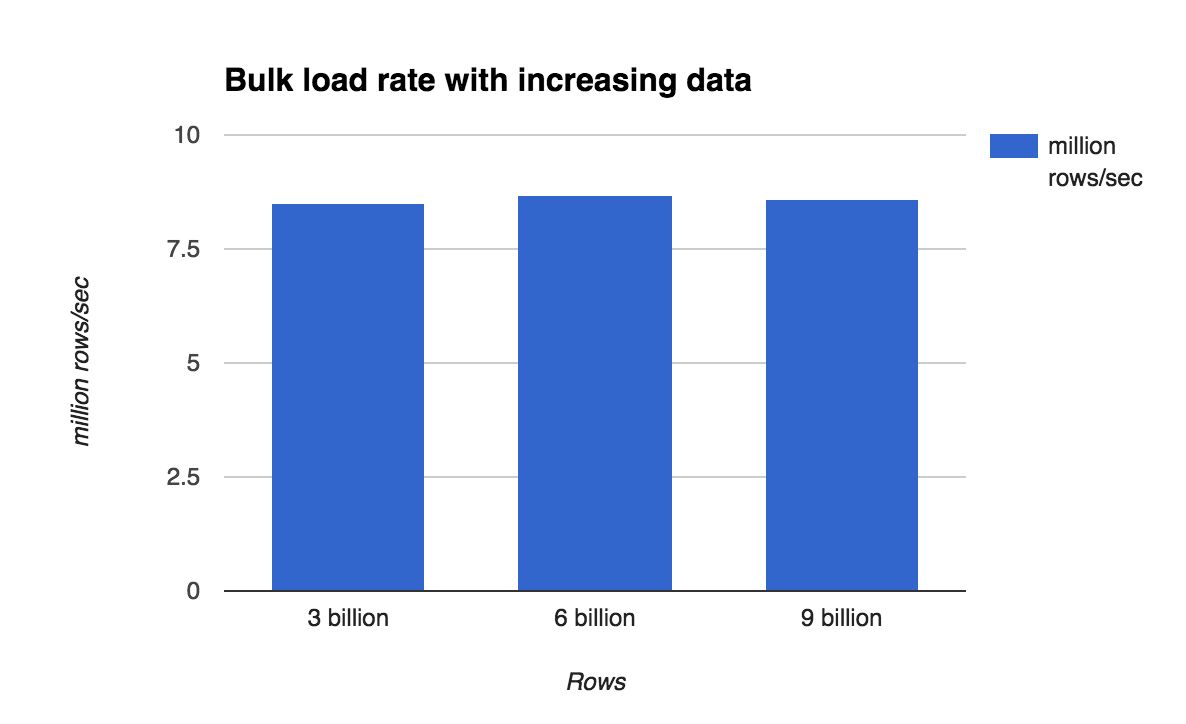 At the end of loading 9 billion rows, the table is close to 1TB in size, but that does not seem to have any negative impact on the load rate.
At the end of loading 9 billion rows, the table is close to 1TB in size, but that does not seem to have any negative impact on the load rate.
Scaling with Coordinators
Let’s first see if adding more coordinators to the cluster has any positive impact on the load time. To measure the impact of additional coordinators, we keep the number of datanodes constant at 16 and vary coordinators from 1 to 3.
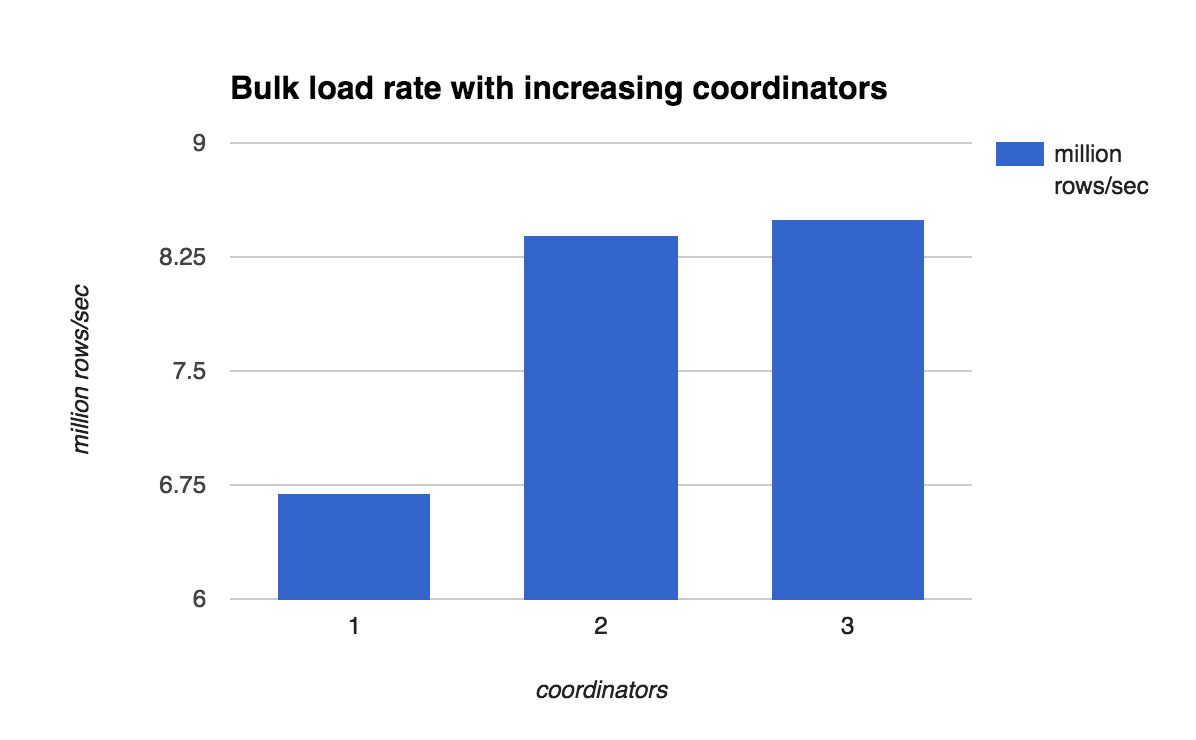
So there is a significant improvement in the ingestion rate when 1 more coordinator is added to the cluster. The rate remains almost the same for 3 coordinators, suggesting that the bottleneck probably shifts to some other place and hence adding the third coordinator does not help much.
Scaling with Datanodes
This is the most interesting bit that should tell us whether Postgres-XL cluster can scale or how well it can scale with addition of more datanodes, as far as data ingestion is concerned. Keeping number of coordinators constant at 2, we vary the number of datanodes from 16 to 20 and again to 24. The following results are obtained by loading 3 billion rows with 24 COPY processes split equally between the two coordinators.
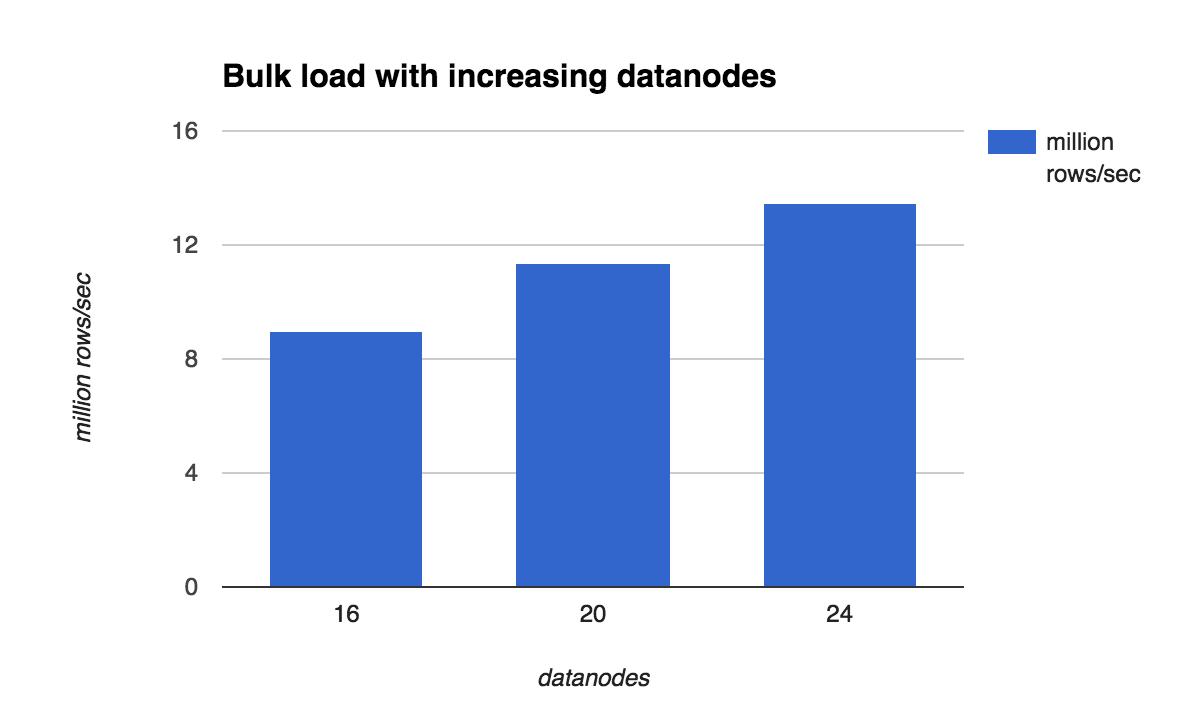
These results are very interesting and they show a linear scalability in ingestion rate with addition of more nodes to the cluster. While we could load at a rate of 13.5M rows/sec or nearly 4.5TB/hr while using 24 datanodes, what’s more interesting to note is that per datanode ingestion rate stays almost constant at about 560K rows/sec. Of course, it may not stay the same if many more datanodes are added since at some point the coordinator may become bottleneck or having too many concurrent sessions at the datanodes may cause performance degradation. A nice thing about Postgres-XL’s architecture is that it allows us to add as many coordinators as we like and hence coordinator side bottleneck is easy to handle, assuming application can split the load between coordinators.
I believe we demonstrated a few important things with these benchmarks.
- Postgres-XL can scale linearly with increasing number of datanodes.
- For large and concurrent bulk load, coordinator may become a bottleneck and it’s advisable to have more than one coordinators for such workloads.
- Postgres-XL can sustain the ingestion rate for very large data. While in these tests, we could achieve the maximum rate of 13.5M rows/sec or 4.5TB/hr, the trend clearly shows that this is nowhere close to the upper limit of Postgres-XL’s ability to handle high concurrent ingestion load.
Thank you for the post. Did you manage to identify the bottleneck after adding the 2nd coordinator?
It’s quite evident that the single coordinator was a bottleneck. But after we added the second coordinator the bottleneck shifted somewhere else because adding third coordinator did not help much. It wasn’t clear if the AWS network became bottleneck at this point or whether the datanodes were fully saturated. The disk utilisation was quite high at datanodes with 2 coordinators, but it’s hard to completely rule out network saturation.
At peak, datanodes were receiving data at about 500 Mbps speed. FWIW I’d observed a simple scp between AWS nodes could only go upto 560 Mbps.