
Random Data
This post continues from my report on Random Numbers.
I have begun working on a random data generator so I want to run some tests to see whether different random number generators actually impact the overall performance of a data generator.
Let’s say we want to create random data for a table with 17 columns, something that contains the details of a company’s order information:
- Order ID
- Line number
- Customer ID
- Part ID
- Supplier ID
- Order date
- Order priority
- Shipping priority
- Quantity
- Item price
- Total price
- Discount
- Revenue
- Cost
- Tax
- Commit date
- Shipping mode
This is intended to illustrate how many random numbers are needed more so than the amount of data this would generate. In this case, these 17 columns of data call for 15 random numbers to be generated per row as the order ID and line number can simply be counters. Thus a total of 90 billion random numbers are needed in order to generate 6 billion rows of data.
The results from the previous random number generator tests suggest that there could be some impact so I want to determine whether:
- the apparent orders of magnitude difference between generators generating numbers will have a significant impact in a program’s performance with generating data.
- the ability to advance the generator will have a significant savings rather than generating numbers.
I only experimented with the MT and PCG Fast generators because that ended up being enough for me to determine which random number generator I wanted to continue using.
Let’s look at the result from generating data with 1, 2, 4 and 8 processes on the same Equinix Metal system that I used previously with 48 processor cores.
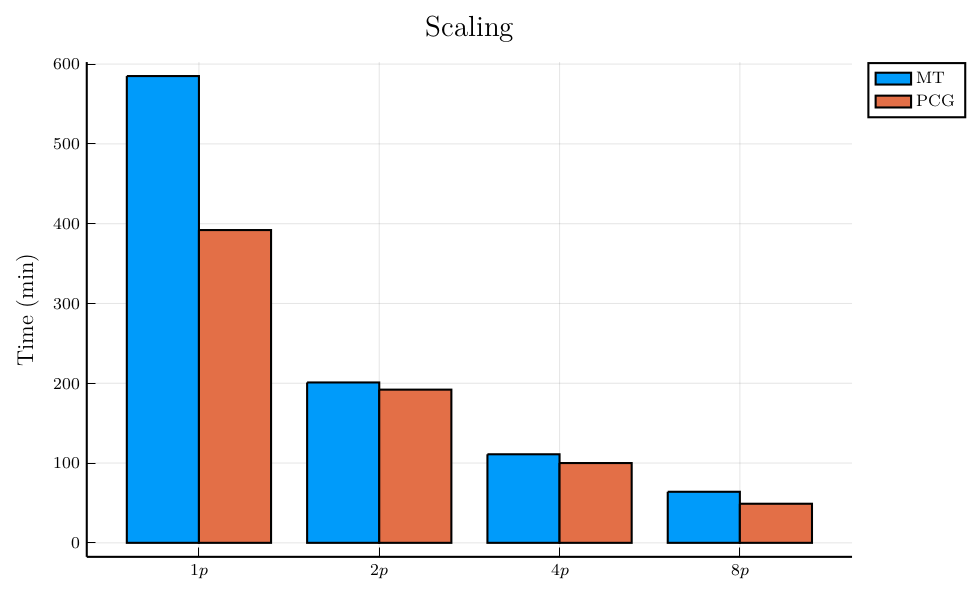
The results from the PCG generator is what I was hoping to see. Two processes generate data twice as fast as one process, four processes reduce the total time further by half and so on.
The results from the MT generator were not what I had expected. When generating data with only one process, the results with the MT generator was 50% slower than the PCG generator, but the results became much closer between the MT and PCG generators when the data generation was split into multiple processes.
I don’t have any explanations for the behavior from the MT generator. It might suggest there is a programming error with generating data with one process. In the interest of time, my takeaway is that the MT generator might not be significantly slower than the PCG generator in an application like this random data generator, and it might not be a huge difference between any of the generators that I’ve looked at thus far when only needing around 100 billion numbers.
Instead of figuring out what happened in the case where one process was used, I was more interested in taking a closer look at the individual data generation times of each process when eight processes were used to parallelize the data generation.
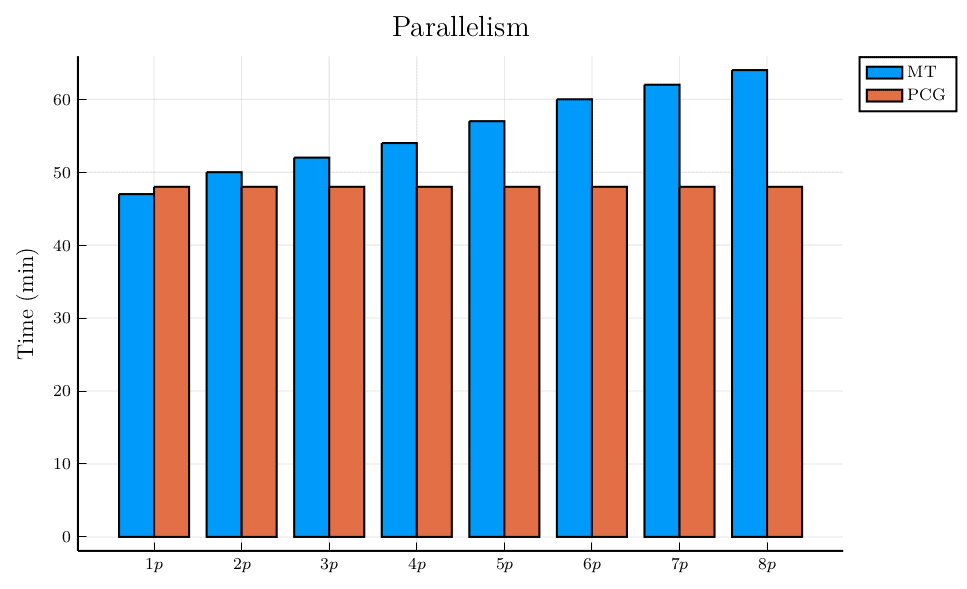
Again, the results from the PCG generator is what I was hoping to see especially with its ability to advance the generator. Each process took more-or-less the same time to generate their respective portions of the data.
Similarly, the results with the MT generator is what I expected to see without the ability to advance the generator. The startup time for each process is increasingly affected by the need to generate numbers before reaching the appropriate point for that portion of the data generation. The time to generate the last chunk of the random data increased by 33%.
Based on these results, it seems that the time spent in the random number generator code is pretty small compared to the rest of the data generator. Extrapolating from the previous tests, 6 of 392 minutes it took to generate data with 1 process using the PCG generator was in the PCG code, which is less than 2% of the time. But there is a significant savings when using a generator that allows you to advance the generator for significantly improved results in parallelism.
There’s one last number to share from implementing the data generator in rust. When comparing a single process of rust versus a single process in C using a PCG generator, the rust program executed 17% faster. There are lots of other differences between simply comparing C to rust on this Debian 10 system between gcc v8.3, rust v1.45.2, and vllvm 7.0.1. But perhaps more at a later time.
Leave a Reply
Want to join the discussion?Feel free to contribute!