

PostgreSQL vs. Linux kernel versions
I’ve published multiple benchmarks comparing different PostgreSQL versions, as for example the performance archaeology talk (evaluating PostgreSQL 7.4 up to 9.4), and all those benchmark assumed fixed environment (hardware, kernel, …). Which is fine in many cases (e.g. when evaluating performance impact of a patch), but on production those things do change over time – you get hardware upgrades and from time to time you get an update with a new kernel version.
For hardware upgrades (better storage, more RAM, faster CPUs, …), the impact is usually fairly easy to predict, and moreover people generally realize they need to assess the impact by analyzing the bottlenecks on production and perhaps even testing the new hardware first.
But for what about kernel updates? Sadly we usually don’t do much benchmarking in this area. The assumption is mostly that new kernels are better than older ones (faster, more efficient, scale to more CPU cores). But is it really true? And how big is the difference? For example what if you upgrade a kernel from 3.0 to 4.7 – will that affect the performance, and if yes, will the performance improve or not?
From time to time we get reports about serious regressions with a particular kernel version, or sudden improvement between kernel versions. So clearly, kernel versions may affects performance.
I’m aware of a single PostgreSQL benchmark comparing different kernel versions, made in 2014 by Sergey Konoplev in response to recommendations to avoid 3.0 – 3.8 kernels. But that benchmark is fairly old (the last kernel version available ~18 months ago was 3.13, while nowadays we have 3.19 and 4.6), so I’ve decided to run some benchmarks with current kernels (and PostgreSQL 9.6beta1).
PostgreSQL vs. kernel versions
But first, let me discuss some significant differences between policies governing commits in the two projects. In PostgreSQL we have the concept of major and minor versions – major versions (e.g. 9.5) are released roughly once a year, and include various new features. Minor versions (e.g. 9.5.2) only include bugfixes, and are released about every three months (or more frequently, when a serious bug is discovered). So there should be no major performance or behavior changes between minor versions, which makes it fairly safe to deploy minor versions without extensive testing.
With kernel versions, the situation is much less clear. Linux kernel also has branches (e.g. 2.6, 3.0 or 4.7), those are by no means equal to “major versions” from PostgreSQL, as they continue to receive new features and not just bugfixes. I’m not claiming that the PostgreSQL versioning policy is somehow automatically superior, but the consequence is that updating between minor kernel versions may easily significantly affect performance or even introduce bugs (e.g. 3.18.37 suffers by OOM issues due to a such non-bugfix commit).
Of course, distributions realize these risks, and often lock the kernel version and do further testing to weed out new bugs. This post however uses vanilla longterm kernels, as available on www.kernel.org.
Benchmark
There are many benchmarks we might use – this post presents a suite of pgbench tests, i.e. a fairly simple OLTP (TPC-B-like) benchmark. I plan to do additional tests with other benchmark types (particularly DWH/DSS-oriented), and I’ll present them on this blog in the future.
Now, back to the pgbench – when I say “collection of tests” I mean combinations of
- read-only vs. read-write
- data set size – active set does (not) fit into shared buffers / RAM
- client count – single client vs. many clients (locking/scheduling)
The values obviously depend on the hardware used, so let’s see what hardware this round of benchmarks was running on:
- CPU: Intel i5-2500k @ 3.3 GHz (3.7 GHz turbo)
- RAM: 8GB (DDR3 @ 1333 MHz)
- storage: 6x Intel SSD DC S3700 in RAID-10 (Linux sw raid)
- filesystem: ext4 with default I/O scheduler (cfq)
So it’s the same machine I’ve used for a number of previous benchmarks – a fairly small machine, not exactly the newest CPU etc. but I believe it’s still a reasonable “small” system.
The benchmark parameters are:
- data set scales: 30, 300 and 1500 (so roughly 450MB, 4.5GB and 22.5GB)
- client counts: 1, 4, 16 (the machine has 4 cores)
For each combination there were 3 read-only runs (15-minute each) and 3 read-write runs (30-minute each). The actual script driving the benchmark is available here (along with results and other useful data).
Note: If you have significantly different hardware (e.g. rotational drives), you may see very different results. If you have a system that you’d like to test, let me know and I’ll help you with that (assuming I’ll be allowed to publish the results).
Kernel versions
Regarding kernel versions, I’ve tested the latest versions in all longterm branches since 2.6.x (2.6.39, 3.0.101, 3.2.81, 3.4.112, 3.10.102, 3.12.61, 3.14.73, 3.16.36, 3.18.38, 4.1.29, 4.4.16, 4.6.5 and 4.7). There’s still a lot of systems running on 2.6.x kernels, so it’s useful to know how much performance you might gain (or lose) by upgrading to a newer kernel. But I’ve been compiling all the kernels on my own (i.e. using vanilla kernels, no distribution-specific patches), and the config files are in the git repository.
Results
As usual, all the data is available on bitbucket, including
- kernel .config file
- benchmark script (run-pgbench.sh)
- PostgreSQL config (with some basic tuning for the hardware)
- PostgreSQL logs
- various system logs (dmesg, sysctl, mount, …)
The following charts show the average tps for each benchmarked case – the results for the three runs are fairly consistent, with ~2% difference between min and max in most cases.
read-only
For the smallest data set, there’s a clear performance drop between 3.4 and 3.10 for all client counts. The results for 16 clients (4x the number of cores) however more than recovers in 3.12.
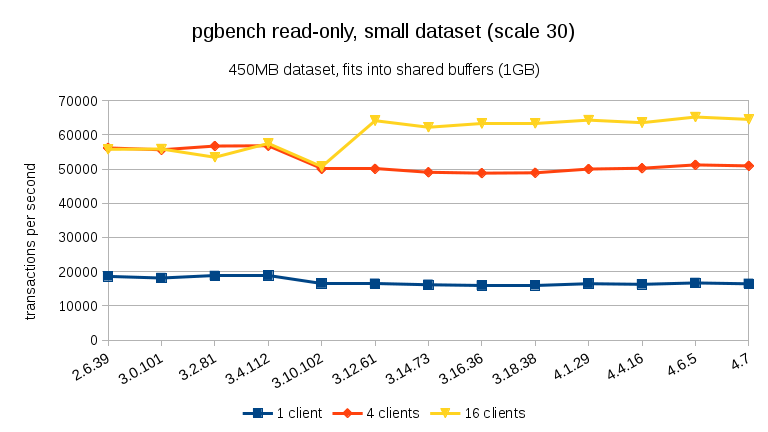
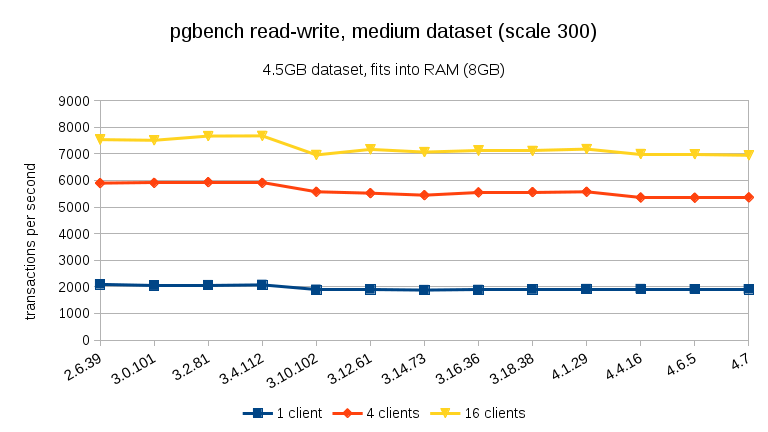
For the medium data set (fits into RAM but not into shared buffers), we can see the same drop between 3.4 and 3.10 but not the recovery in 3.12.
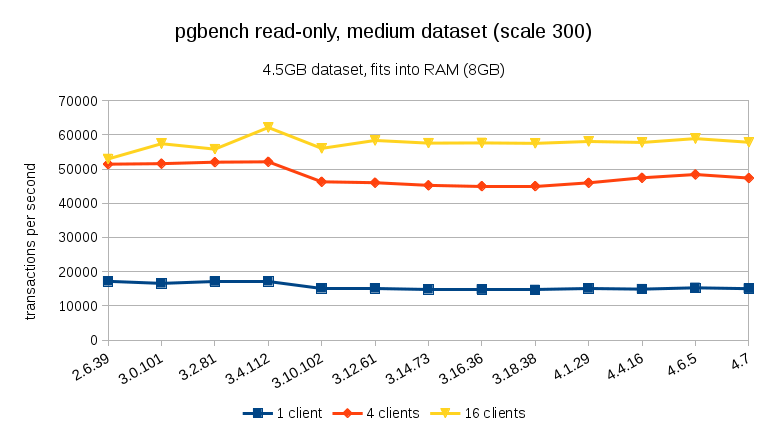
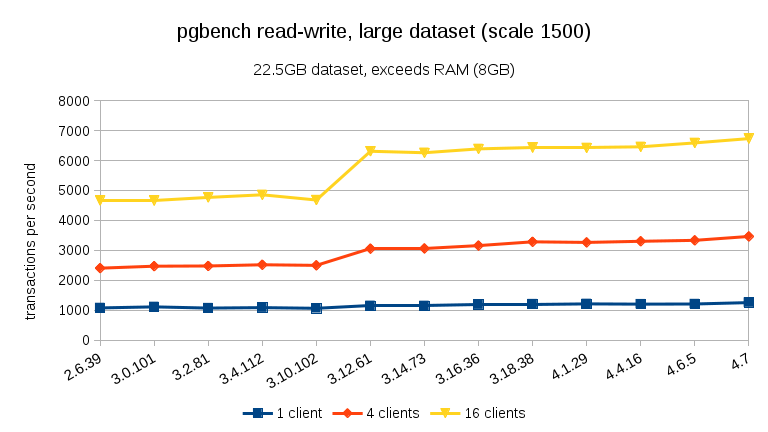
For large data sets (exceeding RAM, so heavily I/O-bound), the results are very different – I’m not sure what happened between 3.10 and 3.12, but the performance improvement (particularly for higher client counts) is quite astonishing.
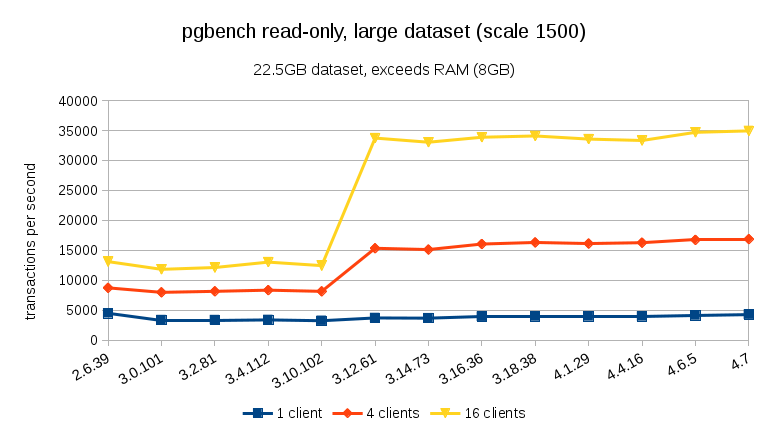
read-write
For the read-write workload, the results are fairly similar. For the small and medium data sets we can observe the same ~10% drop between 3.4 and 3.10, but sadly no recovery in 3.12.
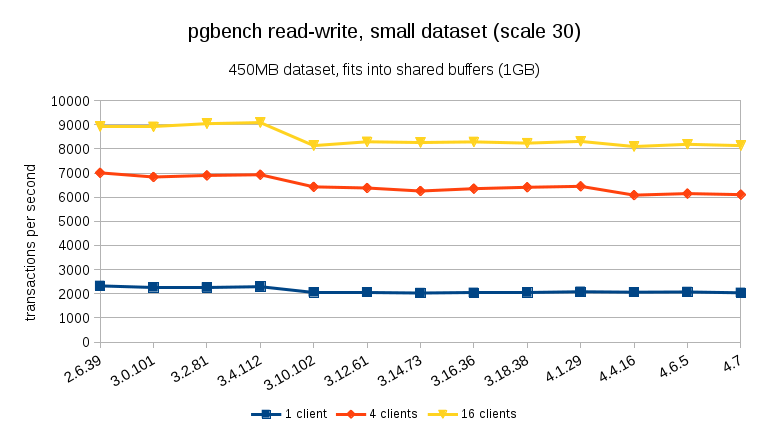
For the large data set (again, significantly I/O bound) we can see similar improvement in 3.12 (not as significant as for the read-only workload, but still significant):
Summary
I don’t dare to draw conclusions from a single benchmark on a single machine, but I think it’s safe to say:
- The overall performance is fairly stable, but we can see some significant performance changes (in both directions).
- With data sets that fit into memory (either into shared_buffers or at least into RAM) we see a measurable performance drop between 3.4 and 3.10. On read-only test this partially recovers in 3.12 (but only for many clients).
- With data sets exceeding memory, and thus primarily I/O-bound, we don’t see any such performance drops but instead a significant improvement in 3.12.
As for the reasons why those sudden changes happen, I’m not quite sure. There are many possibly-relevant commits between the versions, but I’m not sure how to identify the correct one without extensive (and time consuming) testing. If you have other ideas (e.g. are aware of such commits), let me know.
s/PostgreSQL kernel also has branches/The Linux kernel also has branches/
Thanks, fixed.
Git bisection will narrow down a regression between any two commits fairly fast.
Well, I’ve never bisected kernel, but I’d expect that to be a bit more complicated thanks to the reboots. Or is there a better way?
Seems like both the large and medium dataset charts are titled “Medium”, in both parts.
D’oh! Fixed, but it’ll take a few minutes until the images expire from caches/CDN.
What glibc version do you use?
sys-libs/glibc-2.22-r4:2.2::gentoo
Even more helpful would be also including vendor kernels, like the SLES10, SLES11, RHEL6, RHEL7 kernels, which are heavily patched, but based off older Versions.
I guess that is difficult to automate/getting your hands on though?
I agree. Sadly I don’t have enough machines to do all the tests I’d like :-/
But if you have a suitable machine, running the benchmarks is fairly simple (a single shell script will do the trick).
That last two kernels huge reads behaviour difference looks pretty interesting, doesn’t it? But that’s still not it.
I don’t follow. Where do you see huge difference in read behavior for the last two kernels? I don’t see anything like that on any of the charts.
I guess this post was triggered by the mention of changes due to PostgreSQL in 4.7…
https://kernelnewbies.org/Linux_4.7#head-f53f61733cb5cd6ca19e85721ee0fac195b40d61
Perhaps this commit in Linux 3.11 is relevant to the speedup?
http://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=d3922a777f9b4c4df898d326fa940f239af4f9b6
It is mentioned that the ext4 extent cache shrink mechanism, “introduced in kernel 3.9”, had a scalability problem:
https://kernelnewbies.org/Linux_3.11#head-c2b933384f7efdc5b1a26936a92ad8ff2c4413e7
Extent tree leaf block caching in 3.12 strikes me as another possibility:
http://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=107a7bd31ac003e42c0f966aa8e5b26947de6024
But as you say, hard to tell for sure; it could easily be something in memory management or the CPU scheduling.
Thanks for the ideas which patches might be causing the speedup between 3.10 and 3.12! Will look into that.
BTW no, the benchmarking was not triggered by the 4.7 changes (I wasn’t aware of them back in May when starting with this, as there was no 4.7 kernel back then).