
On the impact of full-page writes
While tweaking postgresql.conf, you might have noticed there’s an option called full_page_writes. The comment next to it says something about partial page writes, and people generally leave it set to on – which is a good thing, as I’ll explain later in this post. It’s however useful to understand what full page writes do, because the impact on performance may be quite significant.
Unlike my previous post on checkpoint tuning, this is not a guide how to tune the server. There’s not much you can tweak, really, but I’ll show you how some application-level decisions (e.g. choice of data types) may interact with full page writes.
Partial Writes / Torn Pages
So what are full page writes about? As the comment in postgresql.conf says it’s a way to recover from partial page writes – PostgreSQL uses 8kB pages (by default), but other parts of the stack use different chunk sizes. Linux filesystems typically use 4kB pages (it’s possible to use smaller pages, but 4kB is the max on x86), and at the hardware level the old drives used 512B sectors while new devices often write data in larger chunks (often 4kB or even 8kB).
So when PostgreSQL writes the 8kB page, the other layers of the storage stack may break this into smaller chunks, managed separately. This presents a problem regarding write atomicity. The 8kB PostgreSQL page may be split into two 4kB filesystem pages, and then into 512B sectors. Now, what if the server crashes (power failure, kernel bug, …)?
Even if the server uses storage system designed to deal with such failures (SSDs with capacitors, RAID controllers with batteries, …), the kernel already split the data into 4kB pages. So it’s possible that the database wrote 8kB data page, but only part of that made it to disk before the crash.
At this point you’re now probably thinking that this is exactly why we have transaction log (WAL), and you’re right! So after starting the server, the database will read WAL (since the last completed checkpoint), and apply the changes again to make sure the data files are complete. Simple.
But there’s a catch – the recovery does not apply the changes blindly, it often needs to read the data pages etc. Which assumes that the page is not already borked in some way, for example due to a partial write. Which seems a bit self-contradictory, because to fix data corruption we assume there’s no data corruption.
Full page writes are a way around this conundrum – when modifying a page for the first time after a checkpoint, the whole page is written into WAL. This guarantees that during recovery, the first WAL record touching a page contains the whole page, eliminating the need to read the – possibly broken – page from data file.
Write amplification
Of course, the negative consequence of this is increased WAL size – changing a single byte on the 8kB page will log the whole into WAL. The full page write only happens on the first write after a checkpoint, so making checkpoints less frequent is one way to improve the situation – typically, there’s a short “burst” of full page writes after a checkpoint, and then relatively few full page writes until the end of a checkpoint.
UUID vs. BIGSERIAL keys
But there are some unexpected interactions with design decisions made at the application level. Let’s assume we have a simple table with primary key, either a BIGSERIAL or UUID, and we insert data into it. Will there be a difference in the amount of WAL generated (assuming we insert the same number of rows)?
It seems reasonable to expect both cases to produce about the same amount of WAL, but as the following charts illustrate, there’s a huge difference in practice.
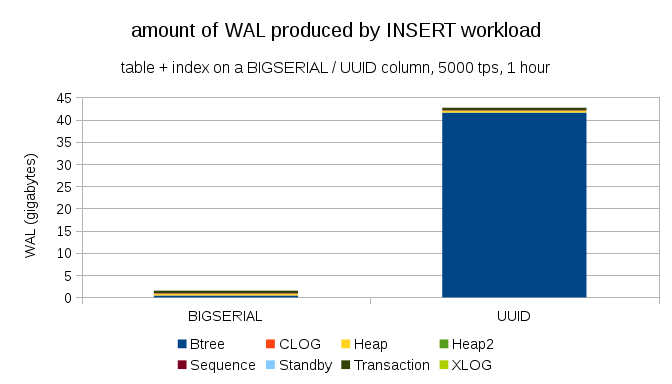
This shows the amount of WAL produced during a 1h benchmark, throttled to 5000 inserts per second. With BIGSERIAL primary key this produces ~2GB of WAL, while with UUID it’s more than 40GB. That’s quite a significant difference, and quite clearly most of the WAL is associated with index backing the primary key. Let’s look as types of WAL records.

Clearly, vast majority of the records are full-page images (FPI), i.e. the result of full-page writes. But why is this happening?
Of course, this is due to the inherent UUID randomness. With BIGSERIAL new are sequential, and so get inserted to the same leaf pages in the btree index. As only the first modification to a page triggers the full-page write, only a tiny fraction of the WAL records are FPIs. With UUID it’s completely different case, of couse – the values are not sequential at all, in fact each insert is likely to touch completely new leaf index leaf page (assuming the index is large enough).
There’s not much the database can do – the workload is simply random in nature, triggering many full-page writes.
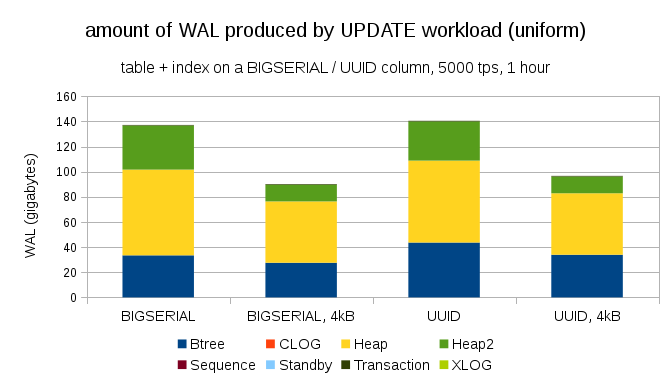
It’s not difficult to get similar write amplification even with BIGSERIAL keys, of course. It only requires different workload – for example with UPDATE workload, randomly updating records with uniform distribution, the chart looks like this:
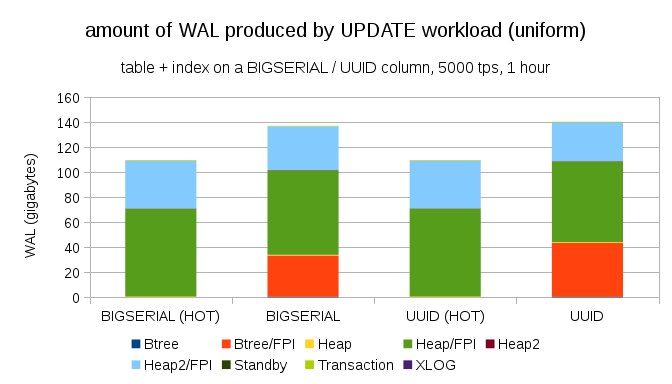
Suddenly, the differences between data types are gone – the access is random in both cases, resulting in almost exactly the same amount of WAL produced. Another difference is that most of the WAL is associated with “heap”, i.e. tables, and not indexes. The “HOT” cases were designed to allow HOT UPDATE optimization (i.e. update without having to touch an index), which pretty much eliminates all index-related WAL traffic.
But you might argue that most applications don’t update the whole data set. Usually, only a small subset of data is “active” – people only access posts from the last few days on a discussion forum, unresolved orders in an e-shop, etc. How does that change the results?
Thankfully, pgbench supports non-uniform distributions, and for example with exponential distribution touching 1% subset of data ~25% of the time, the chart looks like this:
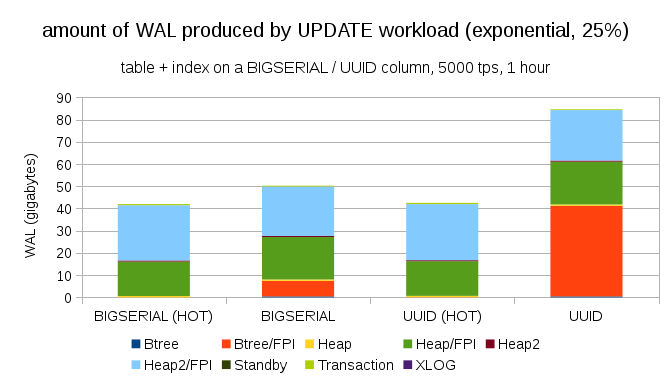
And after making the distribution even more skewed, touching the 1% subset ~75% of the time:
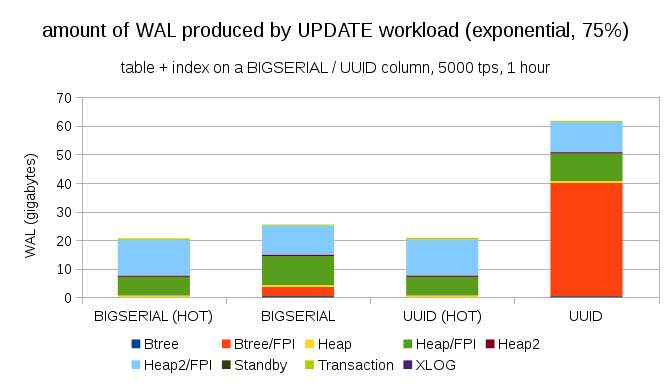
This again shows how big difference the choice of data types may make, and also the importance of tuning for HOT updates.
8kB and 4kB pages
An interesting question is how much WAL traffic could we save by using smaller pages in PostgreSQL (which requires compiling a custom package). In the best case, it might save up to 50% WAL, thanks to logging only 4kB instead of 8kB pages. For the workload with uniformly distributed UPDATEs it looks like this:
So the save is not not exactly 50%, but reduction from ~140GB to ~90GB is still quite significant.
Do we still need full-page writes?
It might seems like a ridiculous after explaining the danger of partial writes, but maybe disabling full page writes might be a viable option, at least in some cases.
Firstly, I wonder whether modern Linux filesystems are still vulnerable to partial writes? The parameter was introduced in PostgreSQL 8.1 released in 2005, so perhaps some of the many filesystem improvements introduced since then make this a non-issue. Probably not universally for arbitrary workloads, but maybe assuming some additional condition (e.g. using 4kB page size in PostgreSQL) would be sufficient? Also, PostgreSQL never overwrites only a subset of the 8kB page – the whole page is always written out.
I’ve done a lot of tests recently trying to trigger a partial write, and I haven’t managed to cause yet a single case. Of course, that’s not really proof the issue does not exist. But even if it’s still an issue, data checksums may be sufficient protection (it won’t fix the issue, but will at least let you know there’s a broken page).
Secondly, many systems nowadays rely on streaming replication replicas – instead of waiting for the server to reboot after a hardware issue (which can take quite a long time) and then spend more time performing recovery, the systems simply switch to a hot standby. If the database on the failed primary is removed (and then cloned from the new primary), partial writes are a non-issue.
But I guess if we started recommending that, then “I don’t know how the data got corrupted, I’ve just set full_page_writes=off on the systems!” would become one of the most common sentences right before death for DBAs (together with the “I’ve seen this snake on reddit, it’s not poisonous.”).
Summary
There’s not much you can do to tune full-page writes directly. For most workloads, most full-page writes happen right after a checkpoint, and then disappear until the next checkpoint. So it’s important to tune checkpoints not to happen too often.
Some application-level decisions may increase randomness of writes to tables and indexes – for example UUID values are inherently random, turning even simple INSERT workload into random index updates. The schema used in the examples was rather trivial – in practice there will be secondary indexes, foreign keys etc. But using BIGSERIAL primary keys internally (and keeping the UUID as surrogate keys) would at least reduce the write amplification.
I’m really interested in discussion about the need for full-page writes on current kernels / filesystems. Sadly I haven’t found many resources, so if you have relevant info, let me know.
Well, we have caught once the situation when we got corruption without FPW (we discovered it because of checksums). That was with 8 KB pages in PostgreSQL, ext4 and RHEL6 kernel (not really modern, but stable). I’m not sure that the reason was exactly in FPW but we switched to physical standby, turned them on everywhere and we haven’t had any corruptions any more.
Yeah, that’s the problem – it’s very difficult to verify the data corruption really was due to FPW. What I was trying to do was disabling FPW, causing data corruption by pulling the plug, and then showing that data corruption disappears after enabling FPW. But I’ve been unable to cause data corruption, even with FPW off.
I’ve seen claims that ZFS, at least, renders FPWs unnecessary. I wonder about BTRFS too. I haven’t yet tested or investigated these deeply.
I strongly suspect that generating torn pages is going to be hard on VMs without plug-pulling the host, and it’s probably harder on SSDs too due to their queuing and caching.
Re turning off FPWs: It’s worth clarifying that relying on replication and turning off FPWs is not in its self safe. You might have undetected corruption due to torn pages that doesn’t actually crash or obviously break the master, or at least not for a while. It might go unnoticed until, say, it’s replicated to your standbys and you’ve recycled your oldest still-good base backups. So I wouldn’t turn FPWs off without enabling data checksums to ensure such problems actually get detected. You hint at this, I just wanted to make it explicit.
It can also be worth looking at turning synchronous_commit = off when you’re relying mainly on replication for data safety and intend to just discard the master and fail over if there’s any problem at all. Or, if your replica is synchronous, setting synchronous_commit = remote_write .
The poor interaction with b-trees and random UUIDs is also a good reason to consider semi-sequential 128-bit keys if you’re going to use UUID or the like. These usually have the high 64 bits as a millisecond timestamp and the low bits as a local sequence’s value and, if needed, a unique node ID fetched from a table or configuration variable. See for example http://rob.conery.io/2014/05/29/a-better-id-generator-for-postgresql/, https://www.depesz.com/2015/10/30/is-c-faster-for-instagram-style-id-generation/ . Petr and I implemented something similar for BDR using 64-bit keys, too.
I’ve seen the claims about ZFS torn-page resilience too, and perhaps it’s true. I very much doubt the other filesystems can be torn-page resilient, because they manage data in 4kB pages – even if they are torn-page resilient at this level, I don’t see how those filesystems could achieve the same thing for 8kB pages used by PostgreSQL. ZFS works around this limitation by having independent ARC cache.
I don’t see how the nature of storage affects this, really. I only mentioned the sector sizes to show that the storage stack uses multiple page sizes, but if you have storage with volatile cache (e.g. on-disk buffer), you’ve already lost and torn pages are only one of the data corruption issues you’re going to see. With reliable storage (caches protected by capacitors etc.) it should not cause torn pages – once the OS hands over data to the storage (e.g. to cache on RAID controller), there should be no torn pages due to the lower storage layers.
I’m not sure I understand your point about silent data corruption on the master – how could that happen assuming you throw away the master in case of power failure?
Semi-sequential UUIDs are a viable solution in many cases, although the randomness may be intentional and reducing it presents information leak (e.g. about timestamp of the insert). Another challenge is that the data is often generated in other parts of the appliacation, not in the database.
Maybe it would be nice to have FPW just for data pages. Corrupted Index is no joy, but they can be easily rebuilt. A corrupted page in a database table causes much more pain.
>But there’s a catch – the recovery does not apply the changes blindly, it often needs to read the data pages etc. Which assumes that the page is not already borked in some way, for example due to a partial write.
I don’t think it works in this way. Partial (non-FPW) WAL store only updated bytes. It’s even not necessary to read old page data to write these updates – just write() the bytes at specified offset – and OS will do the remaining job. Important thing is that not affected data will be kept in its original state, regardless was 8k page update sufficient or was not. After crash recovery WAL updated will be applyed, non updated data be not altered – so page will become valid in any case.
I thought that too, but it’s not the case in practice. For example look at heap_xlog_insert(), i.e. the function applying xl_heap_insert XLOG records:
https://github.com/tvondra/postgres/blob/master/src/backend/access/heap/heapam.c#L8283
In the BLK_NEEDS_REDO the function clearly accesses the page – it calls PageGetMaxOffsetNumber, PageAddItem, PageGetHeapFreeSpace, PageSetLSN and even PageClearAllVisible. Clearly, if the page is sufficiently borked, those calls will fail.
This is necessary because xl_heap_insert (https://github.com/tvondra/postgres/blob/master/src/include/access/heapam_xlog.h#L130) only includes offnum of the tuple (i.e. index of the item pointer in the array), but not position of the tuple data on the page. So with broken page header, this may easily overwrite other data on the page, for example.
Another reason is that recovery checks LSN of the page, and only does recovery if the XLOG record is newer. So if the page gets torn, the first 4kB may be “new” and the second 4kB may be “old” – but as the LSN is in the header, the XLOG recovery will skip the whole page. Of course, this is an optimization and might be disabled unless FPW=on, but that does not address heap_xlog_insert.
Well, there are used some functions which access page data, but they don’t require that page must be not partially stored.
Specifically, PageAddItem() uses overwrite = true flag:
./backend/storage/page/bufpage.c
OffsetNumber
PageAddItem(Page page, Item item, Size size, OffsetNumber offsetNumber,
bool overwrite, bool is_heap)
{
return PageAddItemExtended(page, item, size, offsetNumber,
overwrite ? PAI_OVERWRITE : 0 |
is_heap ? PAI_IS_HEAP : 0);
}
Also, LSN in xl_heap_insert() is only set, but not checked.
Page header is small and is definitely stored atomically (so it cannot become invalid). It’s (at least theoretically) still possible to apply updates on partially stored page (I’m not 100% sure that it is actually implemented – it needs deeper investigations).
I haven’t claimed xl_heap_inserts() checks LSN. That check actually happens much earlier, in XLogReadBufferForRedoExtended, where the LSN for xlog record and page gets compared, and the xlog record is applied only if the page LSN is “older”.
So it’s quite possible that a page gets modified, but only the first 4kB make it to the disk. In that case the page LSN seems fine, the xlog record gets skipped, resulting in data corruption. FPI get recovered unconditionally (without the LSN check), which resolves the issue.
Even if the page header gets written atomically (which may or may not be the case), surely there are places that need to tweak other parts of the page too. For example nbtree code certainly needs to tweak the special part at the end of a page, because that’s where pointers to sibling nodes are.
For example btree_xlog_insert() calls PageAddItem() with overwrite=off, so if the ItemId array gets borked, this will probably fail. And this array is much larger than page header, so unlikely to be stored atomically, at least on some storage devices.
You may be right that theoretically it’s possible, but I was really talking about the current code.
> If the database on the failed primary is removed (and then cloned from the new primary), partial writes are a non-issue.
IMHO you cannot create backup without full page write = on
> IMHO you cannot create backup without full page write = on
Why?
Because reading and writing 8k pages is not atomic.
When pg_basebackup reading data files from FS it get torn pages.
See https://www.postgresql.org/docs/9.6/static/app-pgbasebackup.html
“You will also need to enable full_page_writes on the master.”
That condition only applies to taking backup from hot standby, not from the new master after promotion.
Yes. At master 8k pages r/w is also not atomic and pg_basebackup just enable full_page_write by itself:
https://doxygen.postgresql.org/xlog_8c_source.html#l09937
9936 /*
9937 * Mark backup active in shared memory. We must do full-page WAL writes
9938 * during an on-line backup even if not doing so at other times, because
9939 * it’s quite possible for the backup dump to obtain a “torn” (partially
9940 * written) copy of a database page if it reads the page concurrently with
9941 * our write to the same page.
Sure, but it enables full page writes temporarily, so backups from the master will still work, making the statement “you cannot create backup without full_page_write=on” factually incorrect.
But I agree setting full_page_writes=off may affect backups done in a different way – e.g. by snapshotting a single volume without pg_start_backup/pg_stop_backup demarcation. Or various solutions that rely either on storage-level replication (e.g. DRBD) or shared storage (SAN). Thanks for the comment!
What do you think of combination full_page_writes=off and restart_after_crash=on on master server?
That’s a good question. It boils down to which writes are reliably atomic and which writes may become partial if interrupted by a well-timed crash. In this case, the question is whether a crash of a process (e.g. due to a segfault) can interrupt a write in a different backend, making it partial. PostgreSQL mostly takes the defensive position by assuming the writes may become partial. But as mentioned in the post, I wonder this changes when using 4kB pages (which matches the default x86 memory/filesystem page size) and on modern storage hardware. I’ve been unable to deduce that from kernel / filesystem docs, sadly.
How randomness of UUID will likely to create new leaf page in btree index?
In my understanding as the size of UUID is 128 bits i.e. twice of BIGSERIAL , more number of pages will be required to store the same number of rows and hence there can be increase in WAL size due to FPW .
When compared the index size UUID index is ~2x greater in size.
> But using BIGSERIAL primary keys internally (and keeping the UUID as surrogate keys) would at least reduce the write amplification.
Hmm, doesn’t that _increase_ the write overhead even more because the system now needs to maintain *two* unique indexes? One with the bigint the other with the UUID and both index updates would be written to the WAL
We have an issue of Wal log amplification due to fpi, and too checkpoints happening too frequently. We had to tune the max_wal_size to lower the chance of fpi. What would be a good checkpoint interval for a heavy write database (~ 1 GB per minute or mill rows per minute)