

Evolution of Fault Tolerance in PostgreSQL: Replication Phase
PostgreSQL is an awesome project and it evolves at an amazing rate. We’ll focus on evolution of fault tolerance capabilities in PostgreSQL throughout its versions with a series of blog posts. This is the second post of the series and we’ll talk about replication and its importance on fault tolerance and dependability of PostgreSQL.
If you would like to witness the evolution progress from the beginning, please check the first blog post of the series: Evolution of Fault Tolerance in PostgreSQL
PostgreSQL Replication
Database replication is the term we use to describe the technology used to maintain a copy of a set of data on a remote system. Keeping a reliable copy of a running system is one of the biggest concerns of redundancy and we all like maintainable, easy-to-use and stable copies of our data.
Let’s look at the basic architecture. Typically, individual database servers are referred to as nodes. The whole group of database servers involved in replication is known as a cluster. A database server that allows a user to make changes is known as a master or primary, or may be described as a source of changes. A database server that only allows read-only access is known as a Hot Standby. (Hot Standby term is explained in detailed under Standby Modes title.)
The key aspect of replication is that data changes are captured on a master, and then transferred to other nodes. In some cases, a node may send data changes to other nodes, which is a process known as cascading or relay. Thus, the master is a sending node but not all sending nodes need to be masters. Replication is often categorized by whether more than one master node is allowed, in which case it will be known as multimaster replication.
Let’s see how PostgreSQL is handling replication over time and what is the state-of-art for fault tolerance by the terms of replication.
PostgreSQL Replication History
Historically (around year 2000-2005), Postgres only concentrated in single node fault tolerance/recovery which is mostly achieved by the WAL, transaction log. Fault tolerance is handled partially by MVCC (multi-version concurrency system), but it’s mainly an optimisation.
Write-ahead logging was and still is the biggest fault tolerance method in PostgreSQL. Basically, just having WAL files where you write everything and can recover in terms of failure by replaying them. This was enough for single node architectures and replication is considered to be the best solution for achieving fault tolerance with multiple nodes.
Postgres community used to believe long time that replication is something that Postgres should not provide and should be handled by external tools, this is why tools like Slony and Londiste became existing. (We’ll cover trigger-based replication solutions at the next blog posts of the series.)
Eventually it became clear that, one server tolerance is not enough and more people demanded proper fault tolerance of the hardware and proper way of switching, something in built-in in Postgres. This is when physical (then physical streaming) replication came to life.
We’ll go through all of the replication methods later in the post but let’s see the chronological events of PostgreSQL replication history by major releases:
- PostgreSQL 7.x (~2000)
- Replication should not be part of core Postgres
- Londiste – Slony (trigger based logical replication)
- PostgreSQL 8.0 (2005)
- Point-In-Time Recovery (WAL)
- PostgreSQL 9.0 (2010)
- Streaming Replication (physical)
- PostgreSQL 9.4 (2014)
- Logical Decoding (changeset extraction)
Physical Replication
PostgreSQL solved the core replication need with what most relational databases do; took the WAL and made possible to send it over network. Then these WAL files are applied into a separate Postgres instance that is running read-only.
The read-only standby instance just applies the changes (by WAL) and the only write operations come again from the same WAL log. This is basically how streaming replication mechanism works. In the beginning, replication was originally shipping all files –log shipping-, but later it evolved to streaming.
In log shipping, we were sending whole files via the archive_command. The logic is pretty simple there: you just send the archive and log it to somewhere – like the whole 16MB WAL file – and then you apply it to somewhere, and then you fetch the next one and apply that one and it goes like that. Later on, it became streaming over network by using libpq protocol in PostgreSQL version 9.0.
The existing replication is more properly known as Physical Streaming Replication, since we are streaming a series of physical changes from one node to another. That means that when we insert a row into a table we generate change records for the insert plus all of the index entries.
When we VACUUM a table we also generate change records.
Also, Physical Streaming Replication records all changes at the byte/block level, making it very hard to do anything other than just replay everything

Fig.1 Physical Replication
Fig.1 shows how physical replication works with just two nodes. Client execute queries on the master node, the changes are written to a transaction log (WAL) and copied over network to WAL on the standby node. The recovery process on the standby node then reads the changes from WAL and applies them to the data files just like during crash recovery. If the standby is in hot standby mode, clients may issue read-only queries on the node while this is happening.
Note: Physical Replication simply refers sending WAL files over network from master to standby node. Files can be send by different protocols like scp, rsync, ftp… The difference between Physical Replication and Physical Streaming Replication is Streaming Replication uses an internal protocol for sending WAL files (sender and receiver processes)
Standby Modes
Multiple nodes provide High Availability. For that reason modern architectures usually have standby nodes. There are different modes for standby nodes (warm and hot standby). The list below explains the basic differences between different standby modes, and also shows the case of multi-master architecture.
Warm Standby
Can be activated immediately, but cannot perform useful work until activated. If we continuously feed the series of WAL files to another machine that has been loaded with the same base backup file, we have a warm standby system: at any point we can bring up the second machine and it will have a nearly-current copy of the database. Warm standby does not allow read-only queries, Fig.2 simply represents this fact.
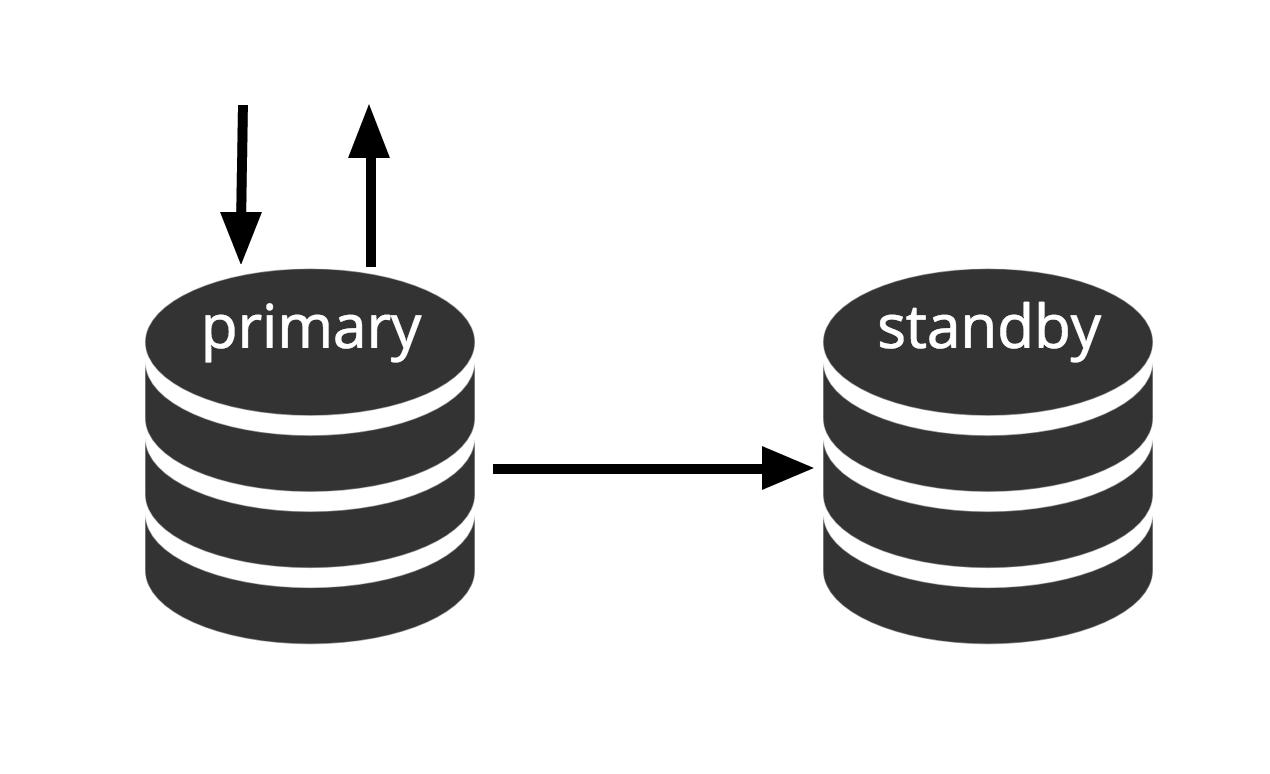
Fig.2 Warm Standby
Recovery performance of a warm standby is sufficiently good that the standby will typically be only moments away from full availability once it has been activated. As a result, this is called a warm standby configuration which offers high availability.
Hot Standby
Hot standby is the term used to describe the ability to connect to the server and run read-only queries while the server is in archive recovery or standby mode. This is useful both for replication purposes and for restoring a backup to a desired state with great precision.
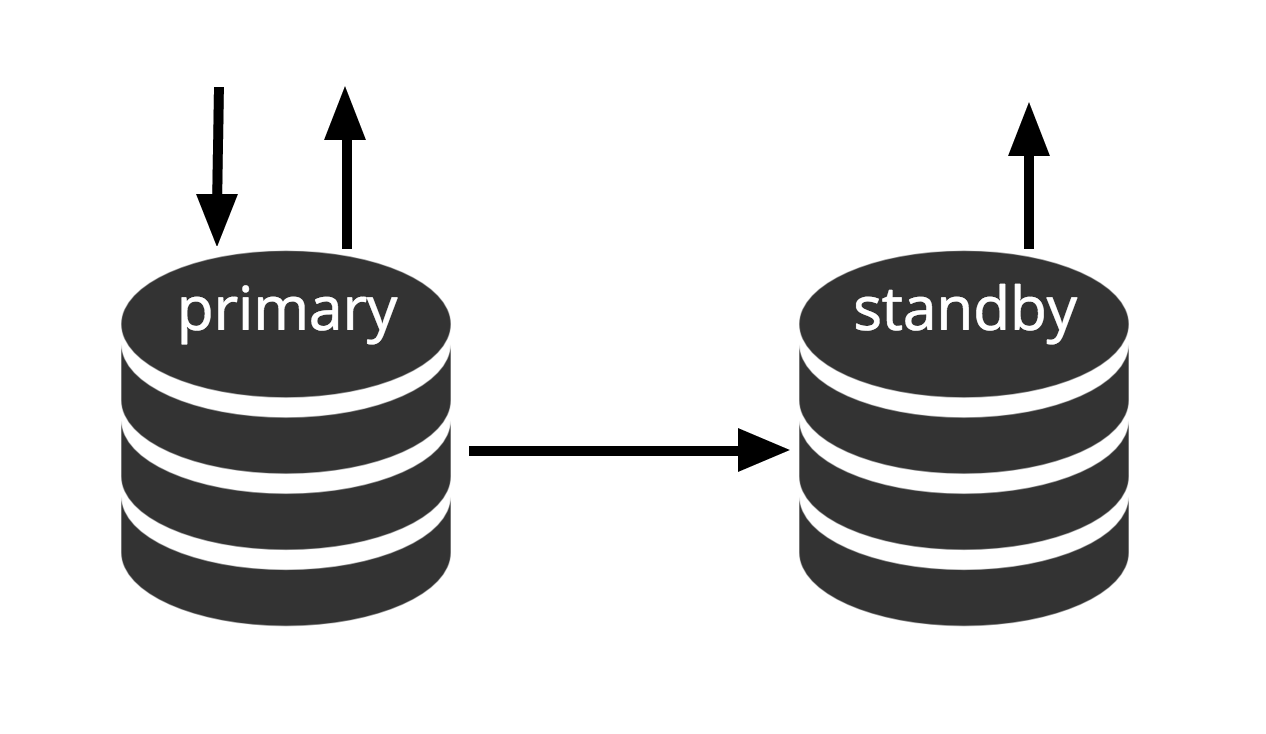 Fig.3 Hot Standby
Fig.3 Hot Standby
The term hot standby also refers to the ability of the server to move from recovery through to normal operation while users continue running queries and/or keep their connections open. Fig.3 shows that standby mode allows read-only queries.
Multi-Master
All nodes can perform read/write work. (We’ll cover multi-master architectures at the next blog posts of the series.)
WAL Level parameter
There is a relation between setting up wal_level parameter in postgresql.conf file and what is this setting is suitable for. I created a table for showing the relation for PostgreSQL version 9.6.

Quick Note:
wal_levelparameter determines how much information is written to the WAL. The default value is minimal, which writes only the information needed to recover from a crash or immediate shutdown. replica adds logging required for WAL archiving as well as information required to run read-only queries on a standby server. Finally, logical adds information necessary to support logical decoding. Each level includes the information logged at all lower levels.In releases prior to 9.6, this parameter also allowed the values archive and hot_standby. These are still accepted but mapped to replica.
Failover and Switchover
In single-master replication, if the master dies, one of the standbys must take its place (promotion). Otherwise, we will not be able to accept new write transactions. Thus, the term designations, master and standby, are just roles that any node can take at some point. To move the master role to another node, we perform a procedure named Switchover.
If the master dies and does not recover, then the more severe role change is known as a Failover. In many ways, these can be similar, but it helps to use different terms for each event. (Knowing the terms of failover and switchover will help us with the understanding of the timeline issues at the next blog post.)
Conclusion
In this blog post we discussed PostgreSQL replication and its importance for providing fault tolerance and dependability. We covered Physical Streaming Replication and talked about Standby Modes for PostgreSQL. We mentioned Failover and Switchover. We’ll continue with PostgreSQL timelines at the next blog post.
References
Logical Replication in PostgreSQL 5432…MeetUs presentation by Petr Jelinek

Why do I configure logical replication steps and states correctly, but records that exist before tables on the main library and newly inserted records do not appear in the standby library? Why?
Cloud=# SELECT * FROM pg_stat_subscription;
– [RECORD 1] – – + – —
SubID 16838
Subname testsub
PID 8050
Relid
Received_lsn 0/18C61B0
Last_msg_send_time 2018-09-16 09:11:07.829583+08
Last_msg_receipt_time 2018-09-16 09:11:07.830084+08
Latest_end_lsn 0/18C61B0
Latest_end_time 2018-09-16 09:11:07.829583+08
The replication status of the main library:
Postgres=# SELECT * FROM pg_stat_replication;
– [RECORD 1] – + – —
PID 8162
Usesysid 10
Usename Postgres
Application_name testsubx
Client_addr 192.168.0.39
Client_hostname
Client_port 42597
Backend_start 2018-09-16 09:09:54.933629+08
Backend_xmin
State streaming
Sent_lsn 0/18C6290
Write_lsn 0/18C6290
Flush_lsn 0/18C6290
Replay_lsn 0/18C6290
Write_lag
Flush_lag
Replay_lag
Sync_priority 0
Sync_state Async
my work setup:
source :
postgres=# CREATE TABLE customers (
postgres(# login text PRIMARY KEY,
postgres(# full_name text NOT NULL,
postgres(# registration_date timestamptz NOT NULL DEFAULT now()
postgres(# );
CREATE TABLE
postgres=# INSERT INTO customers(login, full_name) VALUES(‘john’, ‘John Doe’);
INSERT 0 1
postgres=# CREATE PUBLICATION testpub FOR ALL TABLES;
CREATE PUBLICATION
target:
cloud=# CREATE TABLE customers (
cloud(# login text PRIMARY KEY,
cloud(# full_name text NOT NULL,
cloud(# registration_date timestamptz NOT NULL DEFAULT now()
cloud(# );
CREATE TABLE
cloud=# \c
You are now connected to database “cloud” as user “postgres”.
cloud=# CREATE SUBSCRIPTION testsubx CONNECTION ‘host=192.168.0.39 dbname=cloud’ PUBLICATION testpub;
NOTICE: created replication slot “testsubx” on publisher
CREATE SUBSCRIPTION
— source:
postgres=# select * from customers ;
login | full_name | registration_date
——-+———–+——————————-
john | John Doe | 2018-09-16 09:08:12.613412+08
(1 row)
— target:
cloud=# select * from customers ;
login | full_name | registration_date
——-+———–+——————-
(0 rows)
— refresh replication
cloud=# alter subscription testsubx refresh publication ;
ALTER SUBSCRIPTION
cloud=# select * from customers ;
login | full_name | registration_date
——-+———–+——————-
(0 rows)
why??????????????