
Evolution of Fault Tolerance in PostgreSQL: Time Travel
PostgreSQL is an awesome project and it evolves at an amazing rate. We’ll focus on evolution of fault tolerance capabilities in PostgreSQL throughout its versions with a series of blog posts. This is the third post of the series and we’ll talk about timeline issues and their effects on fault tolerance and dependability of PostgreSQL.
If you would like to witness the evolution progress from the beginning, please check the first two blog posts of the series:
- Evolution of Fault Tolerance in PostgreSQL
- Evolution of Fault Tolerance in PostgreSQL: Replication Phase

Timelines
The ability to restore the database to a previous point in time creates some complexities which we’ll cover some of the cases by explaining failover (Fig. 1), switchover (Fig. 2) and pg_rewind (Fig. 3) cases later in this topic.
For example, in the original history of the database, suppose you dropped a critical table at 5:15PM on Tuesday evening, but didn’t realise your mistake until Wednesday noon. Unfazed, you get out your backup, restore to the point-in-time 5:14PM Tuesday evening, and are up and running. In this history of the database universe, you never dropped the table. But suppose you later realize this wasn’t such a great idea, and would like to return to sometime Wednesday morning in the original history. You won’t be able to if, while your database was up-and-running, it overwrote some of the WAL segment files that led up to the time you now wish you could get back to.
Thus, to avoid this, you need to distinguish the series of WAL records generated after you’ve done a point-in-time recovery from those that were generated in the original database history.
To deal with this problem, PostgreSQL has a notion of timelines. Whenever an archive recovery completes, a new timeline is created to identify the series of WAL records generated after that recovery. The timeline ID number is part of WAL segment file names so a new timeline does not overwrite the WAL data generated by previous timelines. It is in fact possible to archive many different timelines.
Consider the situation where you aren’t quite sure what point-in-time to recover to, and so have to do several pointin-time recoveries by trial and error until you find the best place to branch off from the old history. Without timelines this process would soon generate an unmanageable mess. With timelines, you can recover to any prior state, including states in timeline branches that you abandoned earlier.
Every time a new timeline is created, PostgreSQL creates a ”timeline history” file that shows which timeline it branched off from and when. These history files are necessary to allow the system to pick the right WAL segment files when recovering from an archive that contains multiple timelines. Therefore, they are archived into the WAL archive area just like WAL segment files. The history files are just small text files, so it’s cheap and appropriate to keep them around indefinitely (unlike the segment files which are large). You can, if you like, add comments to a history file to record your own notes about how and why this particular timeline was created. Such comments will be especially valuable when you have a thicket of different timelines as a result of experimentation.
The default behaviour of recovery is to recover along the same timeline that was current when the base backup was taken. If you wish to recover into some child timeline(that is, you want to return to some state that was itself generated after a recovery attempt), you need to specify the target timeline ID in recovery.conf. You cannot recover into timelines that branched off earlier than the base backup.
For simplifying timelines concept in PostgreSQL, timeline related issues in case of failover, switchover and pg_rewind are summarised and explained with Fig.1, Fig.2 and Fig.3.
Failover scenario:
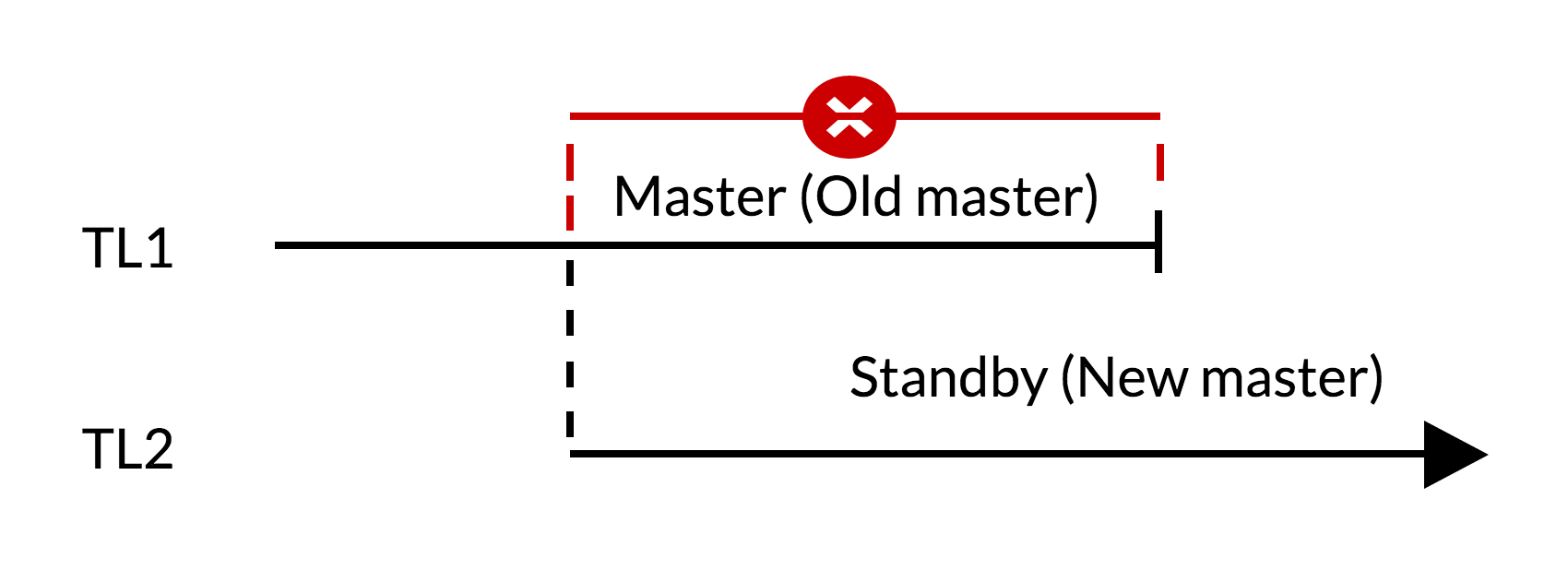
Fig.1 Failover
- There are outstanding changes in the old master (TL1)
- Timeline increase represents new history of changes (TL2)
- Changes from the old timeline can’t be replayed on the servers that switched to new timeline
- The old master can’t follow the new master
Switchover scenario:
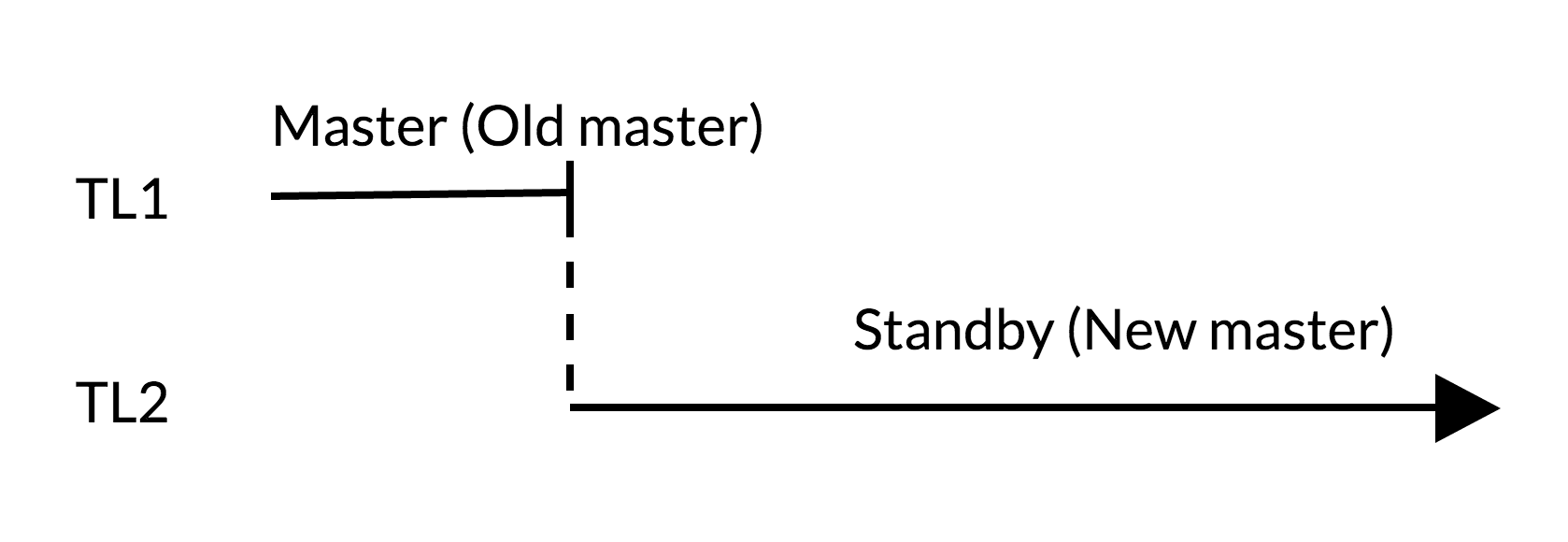 Fig.2 Switchover
Fig.2 Switchover
- There are no outstanding changes in the old master (TL1)
- Timeline increase represents new history of changes (TL2)
- The old master can become standby for the new master
pg_rewind scenario:
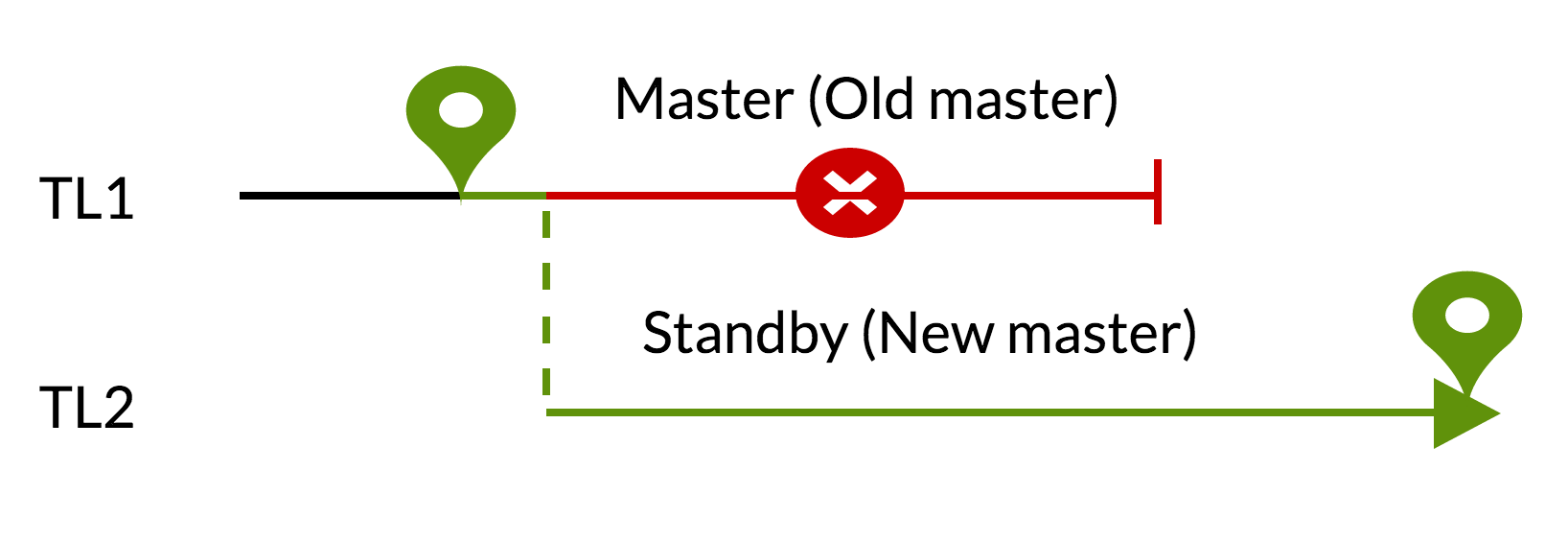 Fig.3 pg_rewind
Fig.3 pg_rewind
- Outstanding changes are removed using data from the new master (TL1)
- The old master can follow the new master (TL2)
pg_rewind
pg_rewind is a tool for synchronising a PostgreSQL cluster with another copy of the same cluster, after the clusters’ timelines have diverged. A typical scenario is to bring an old master server back online after failover, as a standby that follows the new master.
The result is equivalent to replacing the target data directory with the source one. All files are copied, including configuration files. The advantage of pg_rewind over taking a new base backup, or tools like rsync, is that pg_rewind does not require reading through all unchanged files in the cluster. That makes it a lot faster when the database is large and only a small portion of it differs between the clusters.
How it works?
The basic idea is to copy everything from the new cluster to the old cluster, except for the blocks that we know to be the same.
- Scan the WAL log of the old cluster, starting from the last checkpoint before the point where the new cluster’s timeline history forked off from the old cluster. For each WAL record, make a note of the data blocks that were touched. This yields a list of all the data blocks that were changed in the old cluster, after the new cluster forked off.
- Copy all those changed blocks from the new cluster to the old cluster.
- Copy all other files such as clog and configuration files from the new cluster to the old cluster, everything except the relation files.
- Apply the WAL from the new cluster, starting from the checkpoint created at failover. (Strictly speaking, pg_rewind doesn’t apply the WAL, it just creates a backup label file indicating that when PostgreSQL is started, it will start replay from that checkpoint and apply all the required WAL.)
Note: wal_log_hints must be set in postgresql.conf for pg_rewind to be able to work.This parameter can only be set at server start. The default value is off.
Conclusion
In this blog post, we discussed timelines in Postgres and how we handle failover and switchover cases. We also talked about how pg_rewind works and its benefits to Postgres fault tolerance and dependability. We’ll continue with synchronous commit in the next blog post.
References
PostgreSQL Documentation
PostgreSQL 9 Administration Cookbook – Second Edition
pg_rewind Nordic PGDay presentation by Heikki Linnakangas
Leave a Reply
Want to join the discussion?Feel free to contribute!