
Cool Runnings
In an earlier post I commented on a post by Evan Klitzke on his reasons for recommending a move from PostgreSQL to MySQL.
The summary was that the technical details were incorrect, apart from two points. This post returns to those points to discuss what we’ve done about them.
1. When one indexed column is updated then currently all indexes need to be maintained. When you have lots of indexes this causes additional write traffic to disk and to the transaction log. The effect was described as “Write Amplification”, though that term is emotionally charged and implies something non-linear; it would be better to say just simply that the use case could be much more fully optimized than the current state.
My colleague Pavan Deolasee has written a patch to optimize this case better, which he calls the Write Amplification Reduction Method or WARM. That’s a great name because in technical terms the optimization is a relaxation of the HOT optimization, so it’s quite literally a cooler name. But most importantly it works very well, measured at 77% better performance for UPDATEs on tables with 4 indexes and well over 100% performance improvement for cases with more indexes. The patch for that has been submitted to PostgreSQL project for review.
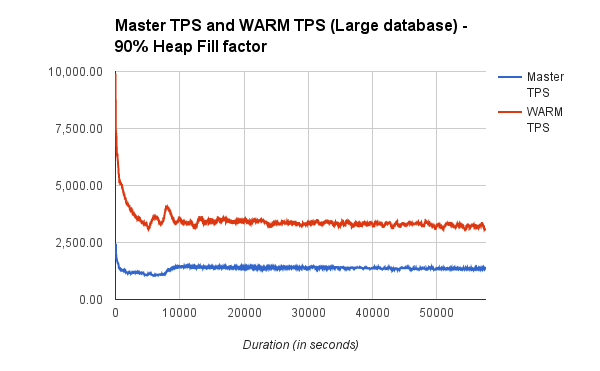
2. PostgreSQL indexes refer to the heap location (via Tuple Identifier, or TID) directly, whereas MySQL secondary indexes refer to the tuple they index indirectly via the Primary Key. For MySQL, this capability avoids some, but not all of the penalty associated with write amplification, though at the cost of slowing down MySQL index reads.
My colleague Alvaro Herrera has developed a prototype for Indirect Indexes for PostgreSQL, based on enhancements to the btree index type. That seems a straightforward feature that we can add to PostgreSQL, though looks like it will work best with integer Primary Keys, much the same as MySQL. We’re seeing a 46% improvement on updates from the worst case. We have more work to do yet before we submit, but that is a pretty good start.
Yes, Evan highlighted some cases where PostgreSQL could benefit from some tuning. So thanks very much for that, we fully and genuinely appreciate that. Again I would highlight that those are not all cases, nor even the common case for most applications.
What I’d like to point out is that it’s about 8 weeks since Evan’s blog was published and we’ve already got two useful and effective solutions to the areas of poor performance highlighted. And what that shows is that these problems are not architectural limitations in the very heart of Postgres, they are just simple use cases that can be tuned, like many others. We’re hopeful that at least one of the above mentioned solutions is likely to get into the next release, PostgreSQL 10.0.
If Evan had come to us with those concerns earlier then we could have fixed them sooner. PostgreSQL is rapidly moving forwards – we made more than 500 improvements in PostgreSQL 9.6 and will be making even more in the future. It’s evolving quickly because we have lots of happy users experimenting with new and interesting use cases, including many technically savvy people who outline what they want to see (like Evan!). Check out the list of some of the other major improvements made in 9.6.
Oh, and if you haven’t seen it, you really should see “Cool Runnings”, the film that is.
I think indirect indexing would have a much greater benefit for GIN indexes where concurrent updates limit the performance.
Agreed. We already have a design to add indirection for GIN indexes, so its on the plan.