

Benchmarking Postgres-XL
As you may have noted from my previous blog, the last few months were busy in getting Postgres-XL up-to-date with the latest 9.5 release of PostgreSQL. Once we had a reasonably stable version of Postgres-XL 9.5, we shifted our attention to measure performance of this brand new version of Postgres-XL. Our choice of the benchmark is largely influenced by the ongoing work on the AXLE project, funded by the European Union under grant agreement 318633. Since we are using TPC BENCHMARK™ H to measure performance of all other work done under this project, we decided to use the same benchmark for evaluating Postgres-XL. It also suits Postgres-XL because TPC-H tries to measure OLAP workloads, something Postgres-XL should do well.
1. Postgres-XL Cluster Setup
Once the benchmark was decided, another big challenge was to find right resources for testing. We did not have access to a large cluster of physical machines. So we did what most would do. We decided to use Amazon AWS for setting up the Postgres-XL cluster. AWS offers a wide range of instances, with each instance type offering different compute or IO power.
This page on AWS shows various available instance types, resources available and their pricing for different regions. It must be noted that the prices and availability may vary from region to region, so its important that you check out all regions. Since Postgres-XL requires low latency and high throughput between its components, it’s also important to instantiate all instances in the same region. For our 3TB TPC-H we decided to go for a 16-datanode cluster of i2.xlarge AWS instances. These instances have 4 vCPU, 30GB of RAM, and 800GB of SSD each, sufficient storage for keeping all the distributed tables, replicated tables (which take more space with increasing size of the cluster), the indexes on them and still leaving enough free space in temporary tablespace for CREATE INDEX and other queries.
2. Benchmark Setup
2.1 TPC Benchmark™ H
The benchmark contains 22 queries with a purpose to examine large volumes of data, execute queries with a high degree of complexity and give answers to critical business questions. We would like to note that the complete TPC Benchmark™ H specification deals with variety of tests such as load, power, and throughput tests. For our testing, we have only run individual queries and not the complete test suite. TPC Benchmark™ H is comprised of a set of business queries designed to exercise system functionalities in a manner representative of complex business analysis applications. These queries have been given a realistic context, portraying the activity of a wholesale supplier to help the reader relate intuitively to the components of the benchmark.
2.2 Database Entities, Relationships, and Characteristics
The components of the TPC-H database are defined to consist of eight separate and individual tables (the Base Tables). The relationships between columns of these tables are illustrated in the following diagram. 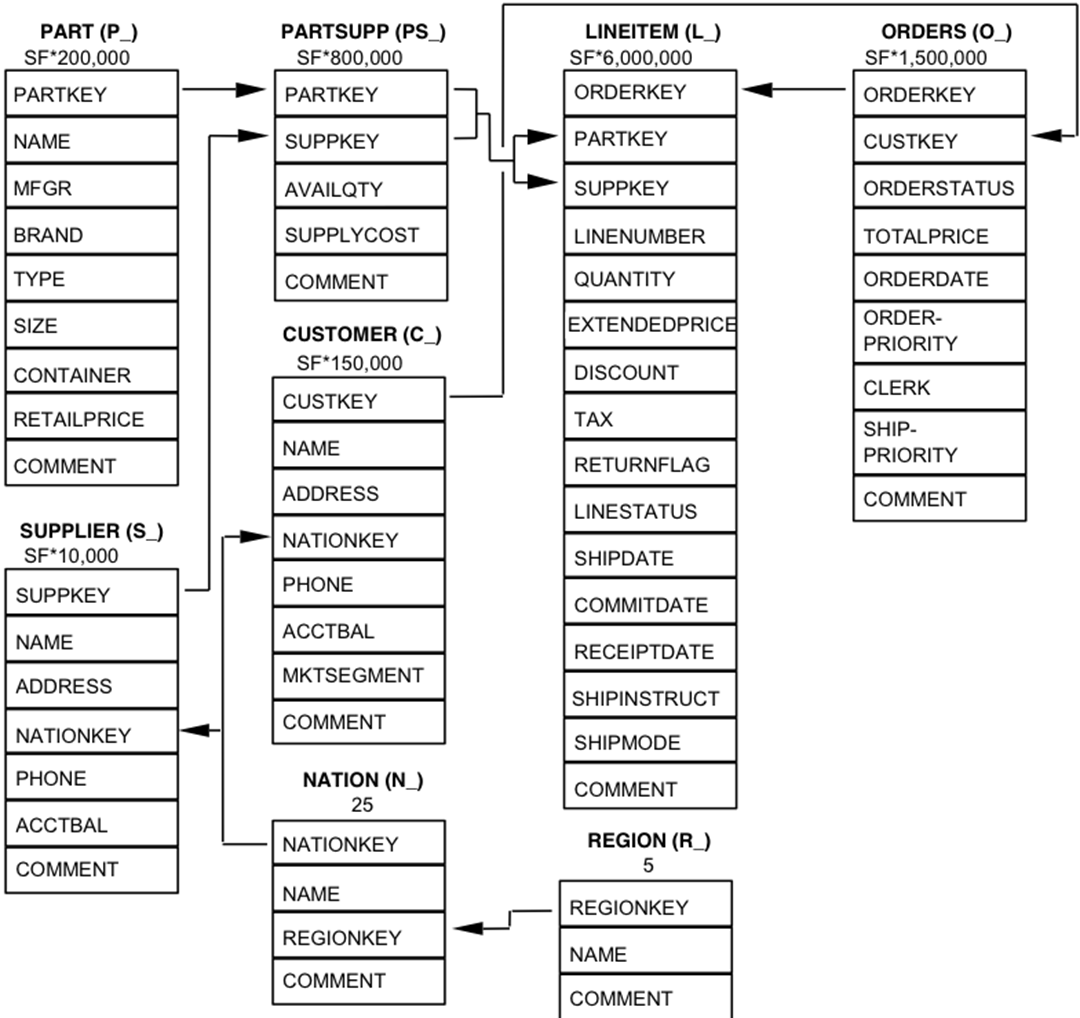 Legend:
Legend:
-
- The parentheses following each table name contain the prefix of the column names for that table;
-
- The arrows point in the direction of the one-to-many relationships between tables
- The number/formula below each table name represents the cardinality (number of rows) of the table. Some are factored by SF, the Scale Factor, to obtain the chosen database size. The cardinality for the LINEITEM table is approximate
2.3 Data Distribution for Postgres-XL
We analyzed all 22 queries in the benchmark and came up with the following data distribution strategy for various tables in the benchmark.
| Table Name | Distribution Strategy |
| LINEITEM | HASH (l_orderkey) |
| ORDERS | HASH (o_orderkey) |
| PART | HASH (p_partkey) |
| PARTSUPP | HASH (ps_partkey) |
| CUSTOMER | REPLICATED |
| SUPPLIER | REPLICATED |
| NATION | REPLICATED |
| REGION | REPLICATED |
Note that LINEITEM and ORDERS which are the largest tables in the benchmark are often joined on the ORDERKEY. So it makes a lot of sense to collocate these tables on the ORDERKEY. Similarly, PART and PARTSUPP are frequently joined on PARTKEY and hence they are collocated on the PARTKEY column. Rest of the tables are replicated to ensure that they can be joined locally, when needed.
3. Benchmark Results
3.1 Load Test
We compared results obtained by running a 3TB TPC-H Load Test on PostgreSQL 9.6 against the 16-node Postgres-XL cluster. The following charts demonstrate the performance characteristics of Postgres-XL.
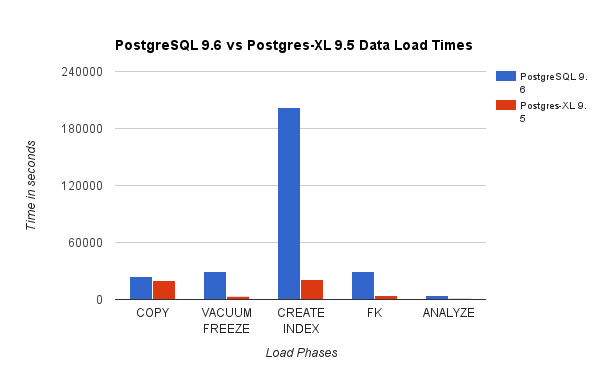 The above chart shows the time taken to complete various phases of a Load Test with PostgreSQL and Postgres-XL. As seen, Postgres-XL performs slightly better for COPY and does a lot better for all other cases. Note: We observed that the coordinator requires a lot of compute power during the COPY phase, especially when more than one COPY streams are running concurrently. To address that, the coordinator was run on a compute optimised AWS instance with 16 vCPU. Alternatively, we could have also run multiple coordinators and distribute compute load between them.
The above chart shows the time taken to complete various phases of a Load Test with PostgreSQL and Postgres-XL. As seen, Postgres-XL performs slightly better for COPY and does a lot better for all other cases. Note: We observed that the coordinator requires a lot of compute power during the COPY phase, especially when more than one COPY streams are running concurrently. To address that, the coordinator was run on a compute optimised AWS instance with 16 vCPU. Alternatively, we could have also run multiple coordinators and distribute compute load between them.
3.2 Power Test
We also compared the query run times for 3TB benchmark on PostgreSQL 9.6 and Postgres-XL 9.5. The following chart shows performance characteristics of the query execution on the two setups.
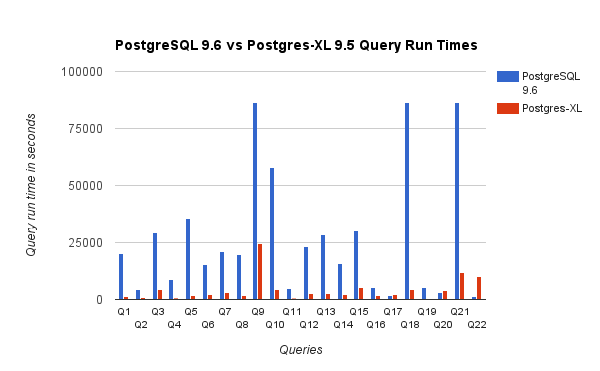 We observed that on average queries ran about 6.4 times faster on Postgres-XL and at least 25% of the queries showed almost linear improvement in performance, in other words they performed nearly 16 times faster on this 16-node Postgres-XL cluster. Furthermore at least 50% of the queries showed 10 times improvement in performance. We further analysed the query performances and concluded that queries that are well partitioned across all available datanodes, such that, there is minimal exchange of data between nodes and without repeated remote execution calls, scale very well in Postgres-XL. Such queries typically have a Remote Subquery Scan node at the top and the subtree under the node is executed on one or more nodes in parallel. Its also common to have some other nodes such as a Limit node or an Aggregate node on top of the Remote Subquery Scan node. Even such queries perform very well on Postgres-XL. Query Q1 is an example of a query that should scale very well with Postgres-XL. On the other hand, queries that require lots of exchange of tuples between datanode-datanode and/or coordinator-datanode may not do well in Postgres-XL. Similarly, queries that require many cross node connections, may also show poor performance. For example, you will notice that the performance of Q22 is bad as compared to a single node PostgreSQL server. When we analysed the query plan for Q22, we observed that there are three levels of nested Remote Subquery Scan nodes in the query plan, where each node opens equal number of connections to the datanodes. Further, the Nest Loop Anti Join has an inner relation with a top level Remote Subquery Scan node and hence for every tuple of the outer relation it has to execute a remote subquery. This results in poor performance of query execution.
We observed that on average queries ran about 6.4 times faster on Postgres-XL and at least 25% of the queries showed almost linear improvement in performance, in other words they performed nearly 16 times faster on this 16-node Postgres-XL cluster. Furthermore at least 50% of the queries showed 10 times improvement in performance. We further analysed the query performances and concluded that queries that are well partitioned across all available datanodes, such that, there is minimal exchange of data between nodes and without repeated remote execution calls, scale very well in Postgres-XL. Such queries typically have a Remote Subquery Scan node at the top and the subtree under the node is executed on one or more nodes in parallel. Its also common to have some other nodes such as a Limit node or an Aggregate node on top of the Remote Subquery Scan node. Even such queries perform very well on Postgres-XL. Query Q1 is an example of a query that should scale very well with Postgres-XL. On the other hand, queries that require lots of exchange of tuples between datanode-datanode and/or coordinator-datanode may not do well in Postgres-XL. Similarly, queries that require many cross node connections, may also show poor performance. For example, you will notice that the performance of Q22 is bad as compared to a single node PostgreSQL server. When we analysed the query plan for Q22, we observed that there are three levels of nested Remote Subquery Scan nodes in the query plan, where each node opens equal number of connections to the datanodes. Further, the Nest Loop Anti Join has an inner relation with a top level Remote Subquery Scan node and hence for every tuple of the outer relation it has to execute a remote subquery. This results in poor performance of query execution.
4. A Few AWS Lessons
While benchmarking Postgres-XL we learnt a few lessons about using AWS. We thought they will be useful for anyone who is looking to use/test Postgres-XL on AWS.
- AWS offers several different types of instances. You must carefully evaluate your work load and amount of storage required before choosing a specific instance type.
- Most of the storage-optimised instances have ephemeral disks attached to them. You don’t need to pay anything additional for those disks, they are attached to the instance and often perform better than EBS. But you must mount them explicitly to be able to use them. Keep in mind though, the data stored on these disks is not permanent and will get wiped out if the instance is stopped. So make sure you’re prepared to handle that situation. Since we were using AWS mostly for benchmarking, we decided to use these ephemeral disks.
- If you are using EBS, make sure you choose appropriate Provisioned IOPS. Too low value will cause very slow IO, but a very high value may increase your AWS bill substantially, especially when dealing with large number of nodes.
- Make sure you start the instances in the same zone to reduce latency and improve throughput for connections between them.
- Make sure you configure instances so that they use private network to talk to each other.
- Look at spot instances. They are relatively cheaper. Since AWS may terminate spot instances at will, for example, if spot price becomes more than your max bid price, be prepared for that. Postgres-XL may become partially or completely unusable depending on which nodes are terminated. AWS supports a concept of launch_group. If multiple instances are grouped in the same launch_group, if AWS decides to terminate one instance, all instances will be terminated.
5. Conclusion
We are able to show, through various benchmarks, that Postgres-XL can scale really well for a large set of real world, complex queries. These benchmarks help us demonstrate Postgres-XL’s capability as an effective solution for OLAP workloads. Our experiments also show that there are some performance issues with Postgres-XL, especially for very large clusters and when the planner makes a bad choice of a plan. We also observed that when there are very large number of concurrent connections to a datanode, performance worsens. We will continue to work on these performance problems. We would also like to test Postgres-XL’s capability as an OLTP solution by using appropriate workloads.
Very interesting.
Did you publish scripts you used to configure and start Postgres-XL on those 16 nodes?
Have you considered testing bigger instances with the same total hourly cost – i.e. 8xi2.2xlarge or 4xi2.4xlarge instances or even 2xi2.8xlarge (those have 10GbE networking)?
Checkout the documentation here:
http://files.postgres-xl.org/documentation/server-start.html
Benchmark scripts are available from the TCP-H site.
http://www.tpc.org/tpch/
These are basically C and SQL files. We need to build them in order to create schema and populate the reference database according to the scale factor that we are targetting to achieve.
There is a bit of customization required to run these scripts.
Great results, one question though:
If the i2.xlarge instances have 800 GB storage, how did you run the 9.6 3 TB serial test for comparison on one of them? Or did you use different hardware for those runs? That is not very clear from this post.
Yes, the tests for vanilla Postgres were done on a different hardware. Here are the specs for that hardware:
– 4x Intel Xeon E54620 Eight Core 2.2GHz Processor
– 256GB (16x16GB) ECC REG System Validated Memory (1333 MHz)
– 2x 250GB SATA 2.5” Enterprise Level HDs (RAID 1, ~250GB)
– 17x 600GB SATA 2.5” Solid State HDs (RAID 0, ~10TB)
– LSI MegaRAID 92718iCC controller and Cache Vault Kit (1GB cache)
The storage layer have been configured as follows:
– 2x 250 GB disks in a RAID 1 for a usable capacity of approximately 229 GiB Small volume for operating system, PostgreSQL installation, logs. etc.
– 17x 600 GB disks in a RAID 0 for a usable capacity of approximately 9.2 TiB Larger RAID, exclusively for storing the benchmarked data files.