
Testing Postgres-XL with DBT-3
As people have been working on merging Postgres-XL with the PostgreSQL 9.5 branch, I’ve been trying out Postgres-XL’s ability to run a decision support-like workload. The DBT-3 test kit, originally developed at the OSDL as a TPC-H derivative, has some new changes so that it can run against Postgres-XL.
I’ll describe how to use DBT-3 and what you can expect it to tell you.
What is DBT-3?
DBT-3 is an open source derivative implementation of the TPC Benchmark(™) H, which is a business oriented ad-hoc decision support workload simulating a parts supplier’s data warehouse. The purpose of DBT-3 is to help characterize system performance to aid in the development of open source solutions. In additional to providing a synthetic workload, this test kit gathers database and operating system statistics and generates a report on the system’s performance.
This workload is composed of three tests called the Load Test, Power Test, and Throughput Test. The kit provides a set of shell scripts to execute these tests, and to make use of the TPC supplied dbgen and qgen programs that generates the table data and queries.
The Load Test measures how long it takes to load data into the database and build indexes.
The Power Test measures an individual’s query processing ability by measure how well a series of twenty-two different queries can be executed.
The Throughput Test measures the system’s ability to process queries issued from multiple users. In other words, it is the simultaneous execution of multiple Power Tests.
DBT-3 is not just for PostgreSQL or Postgres-XL. It has scripts for MySQL too. But I’m just going to talk about the Postgres-XL specific parts here.
How to use DBT-3
These TPC derived test kits are not for the faint of heart but hopefully describing the data that comes out of this test will encourage more testing with large synthetic workloads.
Get the source code
There are currently no easy to use binary distributions so the kit needs to be installed from source. The source code is available here: http://github.com/mw2q/dbt3
The DBT-3 test kit also relies on an additional set of shell scripts to aid in generating a report in HTML: http://github.com/mw2q/dbttools
For ease of use, I’d recommend installing everything into /usr/local. Note that while the DBT-3 kit installs scripts to be used for the test, many of the TPC supplied supporting files are not installed with the scripts.
Installing DBT Tools
The DBT Tools package uses cmake to create a Makefile. Prepare and install the scripts like:
cmake CMakeLists.txt
make install DESTDIR=/usr/local
Installing DBT-3
Because of the way that the TPC provides the data and query generation programs, the kit needs to be configured for the specific database that it is going to be tested. Postgres-XL doesn’t require anything more than what the community PostgreSQL requires and the DBT-3 kit already has a patched dbgen to create data files that can be consumed by PostgreSQL. DBT-3 will install into /usr/local by default. Prepare, build and install the kit like:
./autogen.sh
./configure –with-postgresql
make
make install
Running a Test
While running a small 1GB test against PostgreSQL should be pretty quick on any of today’s personal computers, Postgres-XL may not quite be as simple to try out on a laptop. While Postgres-XL is capable of running all of its components on a single system, separate machines (real or virtual) must be used with DBT-3 because of how the test scripts currently impose a particular cluster configuration.
Postgres-XL Cluster Architecture
This is how the DBT-3 scripts builds a Postgres-XL cluster. One system is setup to provide only the GTM Master and Coordinator nodes. All of the remaining systems provide a Datanode and a GTM Proxy.
In the following examples, we are using 3 virtual machines, named pgxl, pgxl1, and pgxl2. The unenumerated pgxl will have the GTM Master and Coordinator nodes installed, and pgxl1 and pgxl2 will have their own Datanode and GTM Proxy setup.
+-------------+ | GTM Master | | Coordinator | +-------------+ / | \ / | \ / | \ / | \ +-------------+ | +-------------+ | GTM Proxy1 | | GTM Proxy8 | | Datanode1 |--------- ... ---------| Datanode8 | +-------------+ +-------------+
We initially used nine separate systems, one for the GTM Master and Coordinator node, and eight systems each with a GTM Proxy and a Datanode.
There are at least a couple other configurations that would be worth investigating:
- Create multiple Datanodes per system
- Have an additional Coordinator system per datanode, as opposed to a single separate Coordinator system
Setting up the Test environment
The TPC supplied dbgen and qgen programs require environment variables to be set in order to function properly. For illustrative purposes, we are going to assume that the DBT-3 source code was untarred into /opt/dbt3:
- DSS_PATH=/opt/dss_path – Absolute path in which files to load data from are created
- DSS_QUERY=/opt/dbt3/queries/pgsql – Absolute path to the Postgres-XL query templates
- DSS_CONFIG=/opt/dbt3/src/dbgen – directory location for DBGEN configuration files
The DBT-3 kit also needs some environment variables set in order to test against Postgres-XL. The scripts are designed to use the Postgres-XL binaries that are found first in the user’s PATH environment. Be sure to update the PATH setting if the Postgres-XL binaries are not in the system path or are in an isolated location.
The following environment variables are used for both the PostgreSQL and Postgres-XL scripts. They are designed to help automate creating the PostgreSQL and Postgres-XL database instance:
- PGDATABASE=”dbt3” – This is the database name to use
- PGDATA=”/opt/pgdata” – This defines where the database instance will be created
The intent of the next three environment variables is to make the test execution easier. For example, suppose the queries consistently get better plans if the default_statistics_target is set higher than the default. Since these environment variables are passed to pg_ctl, the format needs to look like “-c default_statistics_target=10000”:
- DEFAULT_LOAD_PARAMETERS=”” – Parameters to use for the Load Test
- DEFAULT_POWER_PARAMETERS=”” – Parameters to use for the Power Test
- DEFAULT_THROUGHPUT_PARAMETERS=”” – Parameters to use for the Throughput Test
These next set of environment variables are Postgres-XL specific. The following specifies the details for setting up the system where the GTM Master and Coordinator will be initialized on:
- GTMHOST=”pgxl” – Hostname for the GTM and Coordinator node
- GTMDATA=”$PGDATA/gtm” – Directory to initialized the GTM
- COORDINATORDATA=”$PGDATA/coordinator” – Data directory for the Coordinator
The following specifies the details for the systems where the Datanodes and GTM Proxies will be initialized on:
- HOSTNAMES=”pgxl1 pgxl2″ – A space-delimited list of hostnames for the Datanodes
- GTMPROXYDATA=”$PGDATA/gtm_proxy.” – Data directory prefix for the GTM proxy; the node number will be automatically appended to the end
- DATANODEDATA=”$PGDATA/datanode.” – Data directory prefix for the Datanode. The node number will be automatically appended to the end
These sets of environment variables configure the number of datanodes initialized per system:
- DNPN=1 – Number of datanodes to create per system node
- DNBP=15432 – Starting listener port number for datanodes
- DNBPP=25432 – Starting listener port number for datanode pooler
Start the Test
After setting up the environment variables all that you need to do to run a test is:
dbt3-run-workload -a pgxl -f 1 -o /tmp/results
When the test is complete, all the data collected will be in /tmp/results and an HTML report will be generated. You can point your Web browser to /tmp/results/index.html to view it.
Test Results
Let’s look over some of the details the test report provides, with an 8-node Postgres-XL cluster containing 100GB of data: http://mw2q.github.io/ec2-dnpn1-2s.4/
This test kit is a perpetual work-in-progress and the first thing you may notice is that only hardware details for one of nodes is displayed. Otherwise, the initial page starts by summarizing the version details from the operating system, database management system version, hardware information and test parameters.
A table of test metrics following displaying the scores for each test. The Composite value is calculated from the results from the Load, Power and Throughput Tests. A higher value is better.
The measurement of the Load Test is simply how long the test took to execute, so a lower number is better.
The measurement of the Power Test is geometric mean of the execution time from each of the twenty-two queries. A higher number is better.
The measurement of the Throughput Test is the ratio of the total number of queries executed over the length of the test. A higher number is better.
Finally there is a bar chart showing the execution times for each queries in the Power and Throughput Tests. The Throughput Test numbers are the average of the execution times between all of the streams of queries. The purpose here it to be able to easily identify which queries might need additional work, whether it be query tuning or something in the database engine.
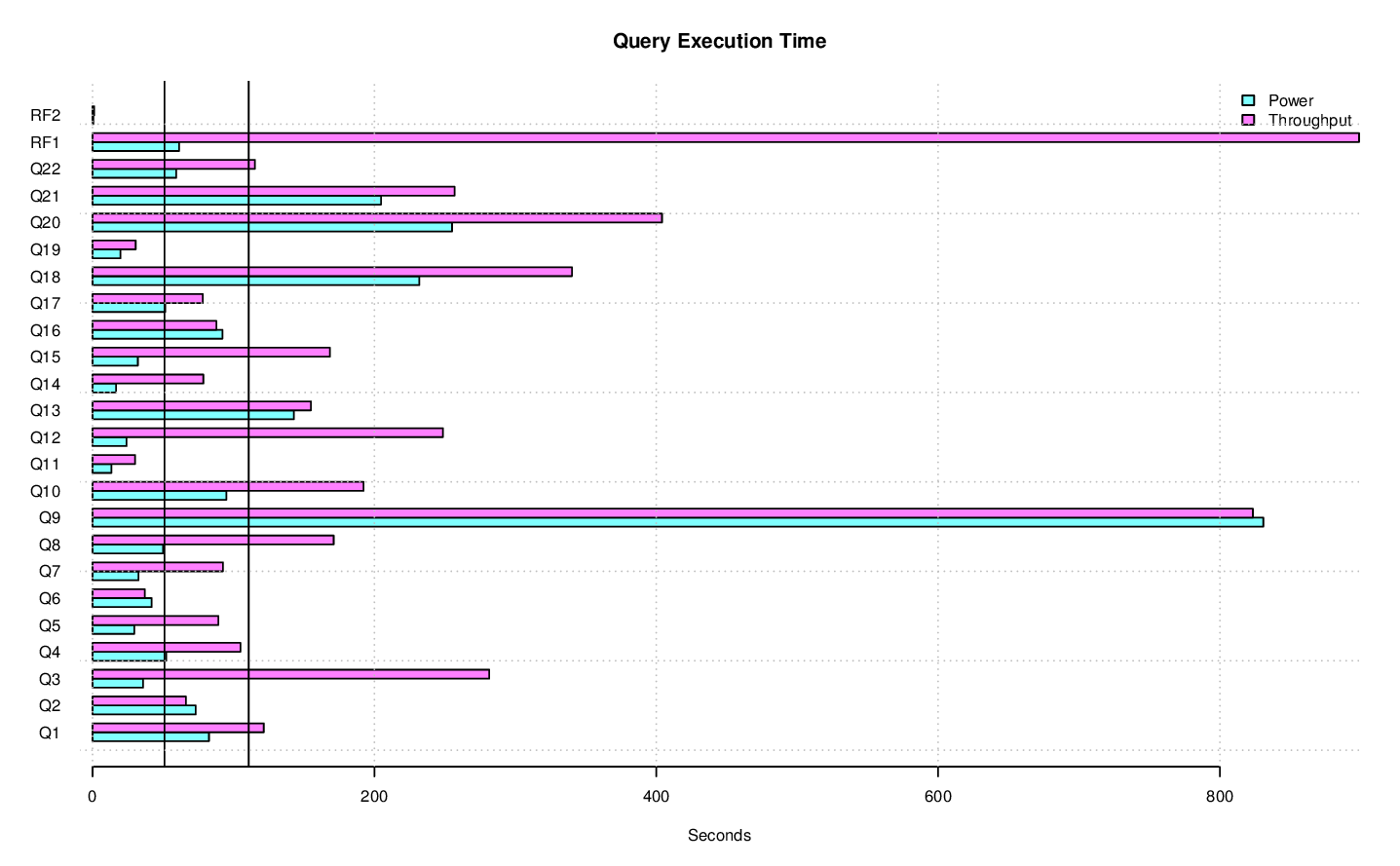
From the initial page there are links to additional system performance details for each of the three tests, and logs from each of the Postgres-XL components.
The Load Test details is really only going to have operating system statistics in the form of charts for processor utilization, i/o, memory, swap and network data. A set of these charts are created per node in the Postgres-XL cluster. The test saves the sar test from each node, so while the kit only creates these particular charts, the sar file can be examined later for other statistics. The detailed database statistics will be lacking, just for the Load Test, because of deficiencies of the scripts to process data that didn’t exist in the first sample. For instance an index that is created after a table is loaded will not be discovered by the post-processing scripts.
The Power and Throughput Test details presents the same charts as the Load Test details, and also provides plans and query results for each of the generated queries. The links under the Query Plans and Query Result both report the actual query that is executed. The Query Plans are only a simple EXPLAIN and I will illustrate later how to get more detailed EXPLAIN output a little further below.
More data!
It will be worth mentioning a couple more options to collect even more data before going into how I’ve used this kit.
Getting more from EXPLAIN
If you pass the -e flag to the dbt3-run-workload script, the kit will execute the queries with EXPLAIN (BUFFERS, ANALYZE). This will change the links to the query results to contain the more detailed EXPLAIN output in place of the query results.
Additionally, if the more detailed EXPLAIN output is captured, an additional script is run during the post-processing to measure plan disasters.
Linux perf Profiles
If you pass -Y to the dbt3-run-workload script, Linux perf will collect data for the Load Test. The Load and Power Test details page will contain additional links at the top of the page to view the profiling reports. In addition to the report, an annotate source report and traces are provided.
While the Load Test generates a single set of Linux perf reports, the Power Test breaks up the data collection per query, so you can see the profile of the system just for one of the queries at a time.
There is no Linux perf data collected for the Throughput test when using Postgres-XL. I haven’t come up with a good way to collect data for multiple-node clusters with how the Throughput Test is executed.
Other use cases
Finding maximum throughput
The measure of the system’s maximum throughput with this workload is determined by how many streams can be run in the Throughput Test. That is fairly straightforward to script to test a series a streams and create separate results directories:
for streams in 2 4 8 10 12 14 16; do
dbt3-run-workload -a pgxl -f 1 \
-o /tmp/results-$streams-streams -n $streams
done
This adds an additional flag, -n, to set the number of streams to execute.
Measuring the effects of a database parameter
Let’s say we want to measure the effect of a database parameter like shared_buffers. Here’s one way to script a series of tests to see what the effects are when shared_buffers is 1, 2, 4, 8, and 16 gigabytes:
for size in 1 2 4 8 16; do
dbt3-run-workload -a pgxl -f 1 -o /tmp/results-${size}gb \
-p “-c shared_buffers=${size}GB” \
-q “-c shared_buffers=${size}GB” \
-r “-c shared_buffers=${size}GB”
done
This example uses three additional command line arguments that pass the database parameter to the database where -p specifies parameters to use for the Load Test, -q for the Power Test, and -r for the Throughput Test.
Testing different filesystems
In a similar way, additional scripting can be done to format the storage device with the filesystem you want to test, and then execute test with the same parameters.
In conclusion
I hope this helps people who are interesting in using the DBT-3 test kit to get some meaningful data. Happy testing!
That was quite a good insight. I am trying to run the same tests and was finding hard to find resources on net. This blog is quite helpful. Lemme retry with the information in here.
So DBT-3 actually sets up the cluster each time it runs?
Is there any way to get it to run on an already setup cluster? I’ve build 2 PGXL9.5 clusters (one with a server per node, another with 2 servers per node) and wanted to compare the perf differences between the two setups.
Thanks!
Yeah, the dbt3-run-workload script currently creates a cluster as part of the Load Test. You can run a Power or Throughput Test without rerunning the Load Test by using the flags -2 and -3, resp, with the dbt3-run-workload script. The individual scripts of the dbt3-load-test script could be executed manually to reload the database without rebuilding the cluster. But there is nothing that helps skip the cluster creation with the wrapper scripts at the moment.
./configure –with-postgresql
should be
“./configure –with-postgresql”
I downloaded the PostgreSQL indexing script from the OSDL DBT-3 benchmark, and I’m amazed at how many indexes it has (35 index) in script.
https://github.com/mw2q/dbt3/blob/master/scripts/pgsql/dbt3-pgsql-load-data
Would you know if the original TPC-H Benchmark has the same number of indexes or smaller number?
I need run benchmark TPC-H in Postgresql dbms (using S.O.Linux debian) with the same number of indexes of the original TPC-H specification.
Anyone know how many secondary indexes exists in the original TPC-H specification and where to find their list?
Best Regards
The dbt3 source link seems to get some problems when loading data with psql copy commands due to not data not corresponding table columns.
But the source you posted on youtube — https://www.youtube.com/watch?v=6gdxbNjQWaY is ok.
I create my own 10 Alhpa2 with one gtm, 2 co nodes, 2 gtm proxyies and 2 datanodes with pghaproxy to route the db connections to the 2 co nodes. But it seemed having problems with Q9 (kind of subquery) , and dbt3 would got wrong column output from querying pg_stat_activity. I had my 10 alpha2 cluster on 3 physical nodes. After checking one of the data nodes log, I found it kept throwing “execute p_1_5cb6_2/p_1_5cb6_2: Remote Subplan” this messages. I am not sure if it’s a bug , or just a version issue. Last night I went home, I setup a 9.5r1 cluster with just gtm , one co and 2 dns on one virtual machine in my notebook , and then ran dbt3 test again. It succeeded !! Ha..Ha…!! I will try 9.5r1 on my physical machines to see what’s going on. To me, PGXL is a very good stuff if MPP management interface can be created , not just pgxc_ctl which is good for implementation. By the way, one cluster crash, it seems to difficult to handle unclean prepared transactions. Any enhancements ??