
PG Phriday: PgBouncer or Bust
What is the role of PgBouncer in a Postgres High Availability stack? What even is PgBouncer at the end of the day? Is it a glorified traffic cop, or an integral component critical to the long-term survival of a Postgres deployment?
When we talk about Postgres High Availability, a lot of terms might spring to mind. Replicas, streaming, disaster recovery, fail-over, automation; it’s a ceaseless litany of architectural concepts and methodologies. The real question is: how do we get from Here to There?
The Importance of Proxies
It’s no secret that the application stack must communicate with the database. Regardless of how many layers of decoupling, queues, and atomicity of our implementation, data must eventually be stored for reference. But where is that endpoint? Presuming that write target is Postgres, what ensures the data reaches that desired terminus?
Consider this diagram:
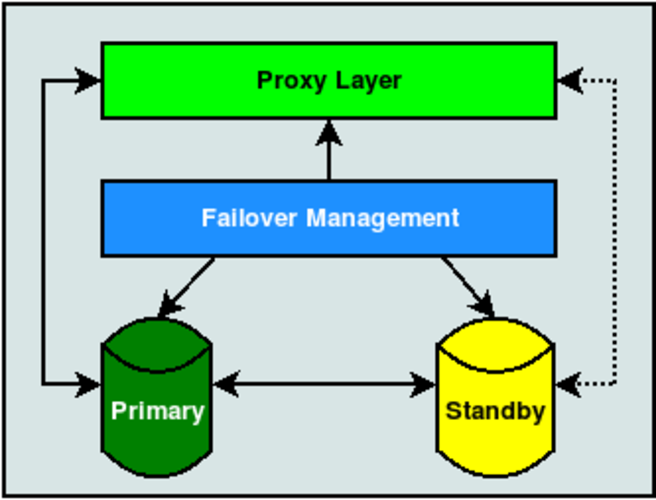
In this case, it doesn’t matter what type of Standby we’re using. It could be a physical streaming replica, some kind of logical copy, or a fully configured BDR node. Likewise, the Failover Mechanism is equally irrelevant. Whether we rely on repmgr, Patroni, Stolon, Pacemaker, or a haphazard collection of ad-hoc scripts, the important part is that we separate the application from the database through some kind of proxy.
Patroni relies on HAProxy and Stolon has its own proxy implementation, but what about the others? Traditionally PgBouncer fills this role. Without this important component, applications must connect directly to either the Primary or post-promotion Standby. If we’re being brutally honest, the application layer can’t be trusted with that kind of responsibility.
But why is that? Simply stated, we don’t know what the application layer is. In reality, an application is anything capable of connecting to the database. That could be the official software, or it could be a report, or a maintenance script, or a query tool, or any number of other access vectors. Which database node are they connecting to, and does it matter?
The proxy layer is one of the rare opportunities as DBAs that we can control the situation, as it is the city where all roads must lead.
VIP, DNS, and Load Balancers
Rather than implement on an additional tier of software, it’s often easier to rely on the old tried-and-true network infrastructure. A virtual IP address for example, requires no extra resources beyond an IP address carved out of a likely liberally allocated internal VPN. DNS is likewise relatively seamless, having command-line manipulation available through utilities like nsupdate.
VIPs unfortunately have a major drawback that may mean they’re inapplicable for failover to a different DC: the assigned ethernet device must be on the same subnet. So if the address is 10.2.5.18, all nodes that wish to use it should be on the 10.2.5.* network. It’s fairly common to have dedicated subnets per Data Center, meaning they can’t share a single VIP. One possible solution to this is to create a subnet that spans both locations, specifically for sharing IP resources.
Another is to use DNS instead. However, this approach may be even worse in the long run. Because name lookups are relatively slow, various levels of caching are literally built into the protocol, and liberally enforced. These caches may be applied at the switch, the drivers, the operating system, a local daemon, and even the application itself. Each one has an independent copy of the cached value, and any changes to a DNS record are only truly propagated when all of these reflect the modification. As a result, the TTL of a DNS record can be a mere fraction of the time it actually takes for all layers to recognize the new target.
During all of this, it would be unsafe to continue utilizing the database layer for risk of split-brain, so applications must be suspended. Clearly that’s undesirable in most circumstances.
Some companies prefer load balancing hardware. This is a panacea of sorts, since such devices act like a VIP without the subnet restriction. Further, these often have programmable interfaces that allow scripts or other software to reconfigure traffic endpoints. This unfortunately relies on extra budgetary constraints that don’t apply to VIP or DNS solutions, making it a resource that isn’t always available.
Software like PgBouncer acts like a virtual approximation of such hardware, with the additional bonus of understanding the Postgres communication protocol. So long as there’s spare hardware, or even a minimally equipped VM, it’s possible to provide decoupled access to Postgres.
Smooth Transitions
One aspect the network-oriented PgBouncer alternatives ignore, is comprehension of the Postgres communication protocol. This is critically important from a High Availability perspective, because it avoids immediately terminating ongoing transactions during manual switches. As a proxy, PgBouncer can react to transaction state, and consequentially avoid interrupting active sessions.
Specifically, version 1.9 of PgBouncer introduced two new features that make this possible where it wasn’t before. It’s now possible to put a server backend into close_needed state. Normally PgBouncer is configured to be either in session mode, where server backends are assigned directly to client connections until they disconnect, or transaction mode, where backends are assigned to new clients after each transaction commit.
In close_needed state, a client that ends its session while in session mode will also close the server backend. Likewise in transaction mode, the server backend is closed and replaced with a new allocation at the end of the current transaction. Essentially we’re now allowed to mark a server backend as stale and in need of replacement at the earliest opportunity without preventing new connections.
Any configuration modification to PgBouncer that affects connection strings will automatically place the affected servers in close_needed state. It’s also possible to manually set close_needed by connecting to the pgbouncer psuedo-database and issuing a RECONNECT command. The implication here is that PgBouncer can be simultaneously connected to Server A and server B without forcing a hard cutover. This allows the application to transition at its leisure if possible.
The secret sauce however, is the server_fast_close configuration parameter. When enabled, PgBouncer will end server backends in close_needed state, even in session mode, provided the current transaction ends. Ultimately this means any in-progress transactions can at least ROLLBACK or COMMIT before their untimely demise. It also means we can redirect database server traffic without interrupting current activity, and without waiting for the transactions themselves to complete.
Previously without these new features, we could only issue PAUSE and RELOAD, and then wait for all connections to finally end of their own accord, or alternatively end them ourselves. Afterward, we could issue RESUME so traffic could reach the new database server target. Now the redirection is immediate, and any lingering transactions can complete as necessary.
This is the power of directly implementing the Postgres client protocol, and it’s something no generic proxy can deliver.
Always Abstract
At this point, it should be fairly evident what options are available. However, we also strongly recommend implementing an abstraction layer of some kind at all times, even when there is only a single database node. Here’s a short list of reasons why:
- One node now doesn’t mean one node forever. As needs evolve and the architecture matures, it may be necessary to implement a full High Availability or Disaster Recovery stack.
- Upgrades don’t care about your uptime requirements. Cross-version software upgrades and hardware replacement upgrades are principally problematic. Don’t get stuck playing Server Musical Chairs.
- Connection pools can be surprisingly necessary. In a world where micro-architectures rule, sending thousands of heterogeneous connections to a single database server could otherwise lead to disaster.
Some of these are possible with VIPs and similar technology, others are limited to the realm of pooling proxies. The important part is that the abstraction layer itself is present. Such a layer can be replaced as requirements evolve, but direct database connections require some kind of transition phase.
Currently only PgBouncer can act as a drop-in replacement for a direct Postgres connection. Software like HAProxy has a TCP mode that essentially masquerades traffic to Postgres, but it suffers from the problem of unceremonious connection disruption on transition. That in itself isn’t necessarily a roadblock, so long as that limitation is considered during architectural planning.
In the end, we like our Postgres abstraction layer to understand Postgres. Visibility into the communication protocol gives PgBouncer the ability to interact with it. Future versions of PgBouncer could, for example, route traffic based on intent, or stack connection target alternates much like Oracle’s TNS Listener.
Yes, it’s Yet Another VM to maintain. On the other hand, it’s less coordination with all of the other internal and external teams to implement and maintain. We’ve merely placed our database black-box into a slightly larger black-box so we can swap out the contents as necessary. Isn’t that what APIs are for, after all?
For read-only queries, I’ve had good luck using HAproxy in TCP mode between pgbouncer and the database. HAporxy is configured to load-balance to streaming replication replicas, and fail over to the primary. pgbouncer provides statistical multiplexing and masks the networking details from the client app.
That’s actually a great use-case. It’s not often you get the opportunity to split read and write traffic like that, but it’s especially handy for load-balancing purposes. That’s one of the scenarios where you can bypass PgBouncer, since HAProxy will remove any offline database servers from the pool.
Great article !
Following up on Fazal message:
I get how you would benefit from using HAproxy between PGbouncer and Read-Only replicas. However I don’t understand how you manage your Writes and Transactions..
Can you explain a bit more ?
Do you also use PGbouncer and HAproxy (in that order) ?
Is it possible to scale PGbouncer (load-balancing on multiple pgbouncers’ instances) or is it a SPOF ?
Finaly, if you’re using pgbouncer before haproxy, you lose the “advantage of pgbouncer (don’t connect every time to db)” and are just using pgbouncer to see if the request should be sent to master or slave..
Can you tell me what I’m missing here ^^
Thx
This is specifically for managing writes. Reads don’t really necessarily care which node they go to, but writes can *only* go to the Primary node. If you control PgBouncer, you control where the writes go; it’s pretty straight-forward. You can use HAProxy round-robin or a load balancer for reads, but your application has to know the difference and use different connections. If your app doesn’t need to write, or only needs to write occasionally, use the connection that’s managed by a failover system. Otherwise, connect to a separate backend pool on HAProxy that just sends your read connection wherever. Or you can create a different db connection mapping for PgBouncer so if you specify a db name (like mydb_readonly) it can specify a different port to the same database name and then connect to a different HAProxy backend definition, so you don’t have to connect to HAProxy directly. Either way, you need two connections; one for when you need writes, and one for when you don’t.
Proxies are not a SPoF, they are a tool. If you have automated failover systems, they must reconfigure every proxy node, if multiple nodes exist. Alternatively you can write your proxy nodes to reach out to a 3rd party resource like a consensus system and configure themselves. We’re working on a product which does exactly that.
You use PgBouncer on *top* of HAProxy normally, so it multiplexes the connections before they reach HAProxy, and thus Postgres. And again, PgBouncer doesn’t send connections to the Primary or Standby, it’s configured to target a specific server by your failover system. It does not have the capability to split read/write requests. It can’t direct traffic on its own, it just sends traffic where you tell it.
The biggest show stopper for using proxies like pgbouncer or haproxy is that it hides the real source IP. Some environments needs to have clear audits logs for many reasons and must have who really connected from where.
It would be nice to have PostgreSQL support of the Proxy Protocol.
https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt
I think that MySQL supports that and it also works with ProxySQL which looks like a very good proxy software. I don’t think PostgreSQL have a feature wise equivalent.
That’s a very good point. We’ve definitely had clients express an interest in tying client IP to the server terminus for auditing purposes. I’ll point this out to the devs we have that occasionally commit to PgBouncer and see if we can’t incorporate that somehow. Thanks for the heads-up!