

Parallelism comes to VACUUM
Vacuum is one of the most important features for reclaiming deleted tuples in tables and indexes. Without vacuum, tables and indexes would continue to grow in size without bounds. This blog post describes the PARALLEL option for VACUUM command, which is newly introduced to PostgreSQL13.
Vacuum Processing Phases
Before discussing the new option in depth let’s review the details of how vacuum works.
Vacuum (without FULL option) consists of five phases. For example, for a table with two indexes, it works as follows:
- Heap scan phase
- Scan the table from the top and collect garbage tuples in memory.
- Index vacuum phase
- Vacuum both indexes one by one.
- Heap vacuum phase
- Vacuum the heap (table).
- Index cleanup phase
- Cleanup both indexes one by one.
- Heap truncation phase
- Truncate empty pages at the end of the table.
In the heap scan phase, vacuum can use the Visibility Map to skip the processing of pages that are known as not having any garbage, while in both the index vacuum phase and the index cleanup phase, depending on index access methods, a whole index scanning is required.
For example, btree indexes, the most popular index type, require a whole index scan to remove garbage tuples and do index cleanup. Since vacuum is always performed by a single process the indexes are processed one by one. The longer execution time of vacuum on especially a large table often annoys the users.
PARALLEL Option
To address this issue, I proposed a patch to parallelize vacuum in 2016. After a long reviewing process and many reforms, the PARALLEL option has been introduced to PostgreSQL 13. With this option, vacuum can perform the Index vacuum phase and index cleanup phase with parallel workers. Parallel vacuum workers launch before entering to either index vacuum phase or index cleanup phase and exit at the end of the phase. An Individual worker is assigned to an index. Parallel vacuum is always disabled in autovacuum.
The PARALLEL option without an integer argument option will automatically calculate the parallel degree based on the number of indexes on the table.
VACUUM (PARALLEL) tbl;
Since the leader process always processes one index, the maximum number of parallel workers will be (the number of indexes in table – 1), which is further limited to max_parallel_maintenance_workers. The target index must be greater than or equal to min_parallel_index_scan_size.
The PARALLEL option allows us to specify the parallel degree by passing a non-zero integer value. The following example uses three workers, for a total of four processes in parallel.
VACUUM (PARALLEL 3) tbl;
The PARALLEL option is enabled by default; to disable parallel vacuum, set max_parallel_maintenance_workers to 0, or specify PARALLEL 0.
VACUUM (PARALLEL 0) tbl; -- disable parallel vacuum
Looking at the VACUUM VERBOSE output, we can see that a worker is processing the index.
The information printed as "by parallel worker" is reported by the worker.
VACUUM (PARALLEL, VERBOSE) tbl; INFO: vacuuming "public.tbl" INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2) INFO: scanned index "i1" to remove 112834 row versions DETAIL: CPU: user: 9.80 s, system: 3.76 s, elapsed: 23.20 s INFO: scanned index "i2" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.64 s, system: 8.98 s, elapsed: 42.84 s INFO: scanned index "i3" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.65 s, system: 8.98 s, elapsed: 43.96 s INFO: "tbl": removed 112834 row versions in 112834 pages DETAIL: CPU: user: 1.12 s, system: 2.31 s, elapsed: 22.01 s INFO: index "i1" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i2" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i3" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: "tbl": found 112834 removable, 112833240 nonremovable row versions in 553105 out of 735295 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 430046 There were 444 unused item identifiers. Skipped 0 pages due to buffer pins, 0 frozen pages. 0 pages are entirely empty. CPU: user: 18.00 s, system: 8.99 s, elapsed: 91.73 s. VACUUM
Index Access Methods Vs degree of parallelism
Vacuum doesn’t always necessarily perform the index vacuum phase and the index cleanup phase in parallel. If the index size is small, or if it’s known that the process can be completed quickly, the cost of launching and managing parallel workers for parallelization causes overhead instead. Depending on the index access methods and its size, it’s better not to perform these phases by a parallel vacuum worker process.
For instance, in vacuuming a large enough btree index, the index vacuum phase of the index can be performed by a parallel vacuum worker because it always requires a whole index scan, while the index cleanup phase is performed by a parallel vacuum worker if the index vacuum is not performed (i.g., there is no garbage on the table). This is because what btree indexes require in the index cleanup phase is to collect the index statistics, which is also collected during the index vacuum phase. On the other hand, hash indexes always don’t require a scan on the index on the index cleanup phase.
To support different types of index vacuum strategies, developers of index access methods can specify these behaviors by setting flags to the amparallelvacuumoptions field of the IndexAmRoutine structure. The available flags are as follows:
- VACUUM_OPTION_NO_PARALLEL (default)
- parallel vacuum is disabled in both phases.
- VACUUM_OPTION_PARALLEL_BULKDEL
- the index vacuum phase can be performed in parallel.
- VACUUM_OPTION_PARALLEL_COND_CLEANUP
- the index cleanup phase can be performed in parallel if the index vacuum phase is not performed yet.
- VACUUM_OPTION_PARALLEL_CLEANUP
- the index cleanup phase can be performed in parallel even if the index vacuum phase has already processed the index.
The table below shows how index AMs built-in PostgreSQL supports parallel vacuum.
| nbtree | hash | gin | gist | spgist | brin | bloom | |
| VACUUM_OPTION_PARALLEL_BULKDEL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| VACUUM_OPTION_PARALLEL_COND_CLEANUP | ✓ | ✓ | ✓ | ||||
| VACUUM_OPTION_CLEANUP | ✓ | ✓ | ✓ |
See ‘src/include/command/vacuum.h‘ for more details.
Performance Verification
I’ve evaluated the performance of parallel vacuum on my laptop (Core i7 2.6GHz, 16GB RAM, 512GB SSD). The table size is 6GB and has eight 3GB indexes. The total relation is 30GB, which doesn’t fit the machine RAM. For each evaluation, I made several percent of the table dirty evenly after vacuuming, then performed vacuum while changing the parallel degree. The graph below shows the vacuum execution time.
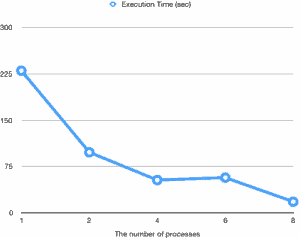
In all evaluations the execution time of the index vacuum accounted for more than 95% of the total execution time. Therefore, parallelization of the index vacuum phase helped to reduce the vacuum execution time much.
Thanks
Special thanks to Amit Kapila for devoted reviewing, providing advice, and committing this feature to PostgreSQL 13. I appreciate all developers who were involved in this feature for reviewing, testing, and discussion.


This is great news, but I see this option is not applicable in combination with FULL – is there a reason for this?
Historically this has been the vacuum we really care about speeding up, as it is done to reclaim precious space on our SSDs due to bloat, but requires our site to be down to do it due to the locks it takes and the size of some tables – many of which are also the most-bloated. (We can approximate some of the savings via index recreation, but this isn’t an ideal solution.)
Perhaps because VACUUM FULL essentially recreates indexes, concurrent index generation in PostgreSQL 11 acts as the equivalent of this? (We ended up skipping from 9.6 to 12 just this year, so have little experience with 10+ features.)