
Loading Tables and Creating B-tree and Block Range Indexes
I have been looking at the new Block Range Indexes (BRIN) being developed for PostgreSQL 9.5. BRIN indexes are designed to provide similar benefits to partitioning, especially for large tables, just without the need to declare partitions. That sounds pretty good but let’s look in greater detail to see if it lives up to the hype.
How large? Here’s one data point. Using the TPC Benchmark(TM) H provided dbgen we created data for the lineitem table at the 10GB scale factor, which results in a 7.2GB text file.
We’re going to compare a couple of basic tasks. The first look will be at the impact of inserting data into a table using the COPY command. We will do a simple experiment of creating a table without any indexes or constraints on it and time how long it takes to load the lineitem data. Then repeat with a B-tree index on one column. And finally repeat again with a BRIN index instead of a B-tree index on the same column.
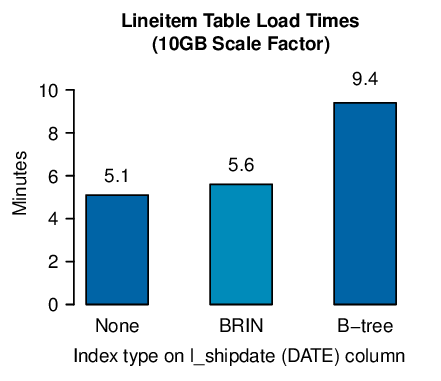 The above bar plot shows the average times over five measurements. Our baseline of loading the lineitem table without any indexes averaged 5.1 minutes. Once a B-tree index was added to the i_shipdate DATE column, the average load time increased to 9.4 minutes, or by 85%. When the B-three index was replaced by a BRIN index, the load time only increased to 5.6 minutes, or by 11%.
The above bar plot shows the average times over five measurements. Our baseline of loading the lineitem table without any indexes averaged 5.1 minutes. Once a B-tree index was added to the i_shipdate DATE column, the average load time increased to 9.4 minutes, or by 85%. When the B-three index was replaced by a BRIN index, the load time only increased to 5.6 minutes, or by 11%.
The next experiment is to average how long it takes to create a B-tree index on a table that is already populated with data. Then repeat that with a BRIN index. This will be done on the same i_shipdate DATE column and repeated for a total of five measurements each.
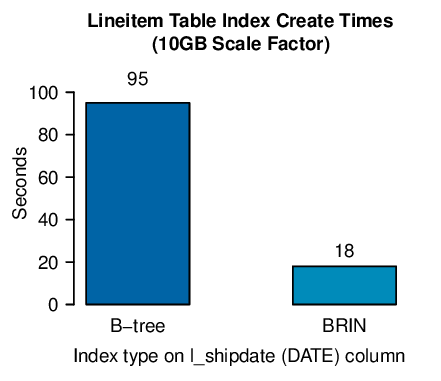
The B-tree index took 95 seconds to build, where the BRIN index 18 seconds to build, an 80% improvement.
That’s very encouraging. The overhead to loading data into a table from a single BRIN index is only 11%, and reduced the total load time by 40% when compared to having a B-tree index. And creating a new BRIN index takes only 20% of the time that a new B-tree index would take. We will have more experiments lined up to see where else BRIN indexes may or may not benefit us.
The research leading to these results has received funding from the European Union’s Seventh Framework Programme (FP7/2007-2013) under grant agreement n°318633 – the AXLE project – http://www.axleproject.eu
Looking forward to see some OLTP/OLAP read benchmarks.