

How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 2
This is the second installment of a two-part series on 2ndQuadrant’s repmgr, an open-source high-availability tool for PostgreSQL.
In the first part, we set up a three-node PostgreSQL 12 cluster along with a “witness” node. The cluster consisted of a primary node and two standby nodes. The cluster and the witness node were hosted in an Amazon Web Service Virtual Private Cloud (VPC). The EC2 servers hosting the Postgres instances were placed in subnets in different availability zones (AZ), as shown below:

We will make extensive references to the node names and their IP addresses, so here is the table again with the nodes’ details:
| Node Name | IP Address | Role | Apps Running |
| PG-Node1 | 16.0.1.156 | Primary | PostgreSQL 12 and repmgr |
| PG-Node2 | 16.0.2.249 | Standby 1 | PostgreSQL 12 and repmgr |
| PG-Node3 | 16.0.3.52 | Standby 2 | PostgreSQL 12 and repmgr |
| PG-Node-Witness | 16.0.1.37 | Witness | PostgreSQL 12 and repmgr |
We installed repmgr in the primary and standby nodes and then registered the primary node with repmgr. We then cloned both the standby nodes from the primary and started them. Both the standby nodes were also registered with repmgr. The “repmgr cluster show” command showed us everything was running as expected:

Current Problem
Setting up streaming replication with repmgr is very simple. What we need to do next is to ensure the cluster will function even when the primary becomes unavailable. This is what we will cover in this article.
In PostgreSQL replication, a primary can become unavailable for a few reasons. For example:
- The operating system of the primary node can crash, or become unresponsive
- The primary node can lose its network connectivit
- The PostgreSQL service in the primary node can crash, stop, or become unavailable unexpectedly
- The PostgreSQL service in the primary node can be stopped intentionally or accidentally
Whenever a primary becomes unavailable, a standby does not automatically promote itself to the primary role. A standby still continues to serve read-only queries – although the data will be current up to the last LSN received from the primary. Any attempt for a write operation will fail.
There are two ways to mitigate this:
- The standby is manually upgraded to a primary role. This is usually the case for a planned failover or “switchover”
- The standby is automatically promoted to a primary role. This is the case with non-native tools that continuously monitor replication and take recovery action when the primary is unavailable. repmgr is one such tool.
We will consider the second scenario here. This situation has some extra challenges though:
- If there are more than one standbys, how does the tool (or the standbys) decide which one is to be promoted as primary? How does the quorum and the promotion process work?
- For multiple standbys, if one is made primary, how do the other nodes start “following it” as the new primary?
- What happens if the primary is functioning, but for some reason temporarily detached from the network? If one of the standbys is promoted to primary and then the original primary comes back online, how can a “split brain” situation be avoided?
remgr’s Answer: Witness Node and the repmgr Daemon
To answer these questions, repmgr uses something called a witness node. When the primary is unavailable – it is the witness node’s job to help the standbys reach a quorum if one of them should be promoted to a primary role. The standbys reach this quorum by determining if the primary node is actually offline or only temporarily unavailable. The witness node should be located in the same data centre/network segment/subnet as the primary node, but must NEVER run on the same physical host as the primary node.
Remember that in the first part of this series, we rolled out a witness node in the same availability zone and subnet as the primary node. We named it PG-Node-Witness and installed a PostgreSQL 12 instance there. In this post, we will install repmgr there as well, but more on that later.
The second component of the solution is the repmgr daemon (repmgrd) running in all nodes of the cluster and the witness node. Again, we did not start this daemon in the first part of this series, but we will do so here. The daemon comes as part of the repmgr package – when enabled, it runs as a regular service and continuously monitors the cluster’s health. It initiates a failover when a quorum is reached about the primary being offline. Not only can it automatically promote a standby, it can also reinitiate other standbys in a multi-node cluster to follow the new primary.
The Quorum Process
When a standby realizes it cannot see the primary, it consults with other standbys. All the standbys running in the cluster reach a quorum to choose a new primary using a series of checks:
- Each standby interrogates other standbys about the time it last “saw” the primary. If a standby’s last replicated LSN or the time of last communication with the primary is more recent than the current node’s last replicated LSN or the time of last communication, the node does not do anything and waits for the communication with the primary to be restored
- If none of the standbys can see the primary, they check if the witness node is available. If the witness node cannot be reached either, the standbys assume there is a network outage on the primary side and do not proceed to choose a new primary
- If the witness can be reached, the standbys assume the primary is down and proceed to choose a primary
- The node that was configured as the “preferred” primary will then be promoted. Each standby will have its replication reinitialized to follow the new primary.
Configuring the Cluster for Automatic Failover
We will now configure the cluster and the witness node for automatic failover.
Step 1: Install and Configure repmgr in Witness
We already saw how to install the repmgr package in our last article. We do this in the witness node as well:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
And then:
# yum install repmgr12 -y
Next, we add the following lines in the witness node’s postgresql.conf file:
listen_addresses = '*' shared_preload_libraries = 'repmgr'
We also add the following lines in the pg_hba.conf file in the witness node. Note how we are using the CIDR range of the cluster instead of specifying individual IP addresses.
local replication repmgr trust host replication repmgr 127.0.0.1/32 trust host replication repmgr 16.0.0.0/16 trust local repmgr repmgr trust host repmgr repmgr 127.0.0.1/32 trust host repmgr repmgr 16.0.0.0/16 trust
Note
[The steps described here are for demonstration purposes only. Our example here is using externally reachable IPs for the nodes. Using listen_address = ‘*’ along with pg_hba’s “trust” security mechanism therefore poses a security risk, and should NOT be used in production scenarios. In a production system, the nodes will all be inside one or more private subnets, reachable via private IPs from jumphosts.]
With postgresql.conf and pg_hba.conf changes done, we create the repmgr user and the repmgr database in the witness, and change the repmgr user’s default search path:
[postgres@PG-Node-Witness ~]$ createuser --superuser repmgr
[postgres@PG-Node-Witness ~]$ createdb --owner=repmgr repmgr
[postgres@PG-Node-Witness ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"
Finally, we add the following lines to the repmgr.conf file, located under /etc/repmgr/12/
node_id=4 node_name='PG-Node-Witness' conninfo='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2' data_directory='/var/lib/pgsql/12/data'
Once the config parameters are set, we restart the PostgreSQL service in the witness node:
# systemctl restart postgresql-12.service
To test the connectivity to witness node repmgr, we can run this command from the primary node:
[postgres@PG-Node1 ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'
Next, we register the witness node with repmgr by running the “repmgr witness register” command as the postgres user. Note how we are using the address of the primary node, and NOT the witness node in the command below:
[postgres@PG-Node-Witness ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf witness register -h 16.0.1.156
This is because the “repmgr witness register” command adds the witness node’s metadata to primary node’s repmgr database, and if necessary, initialises the witness node by installing the repmgr extension and copying the repmgr metadata to the witness node.
The output will look like this:
INFO: connecting to witness node "PG-Node-Witness" (ID: 4) INFO: connecting to primary node NOTICE: attempting to install extension "repmgr" NOTICE: "repmgr" extension successfully installed INFO: witness registration complete NOTICE: witness node "PG-Node-Witness" (ID: 4) successfully registered
Finally, we check the status of the overall setup from any node:
[postgres@PG-Node-Witness ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output looks like this:

Step 2: Modifying the sudoers File
With the cluster and the witness running, we add the following lines in the sudoers file In each node of the cluster and the witness node:
Defaults:postgres !requiretty postgres ALL = NOPASSWD: /usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service, /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.service
Step 3: Configuring repmgrd Parameters
We have already added four parameters in the repmgr.conf file in each node. The parameters added are the basic ones needed for repmgr operation. To enable the repmgr daemon and automatic failover, a number of other parameters need to be enabled/added. In the following subsections, we will describe each parameter and the value they will be set to in each node.
failover
The failover parameter is one of the mandatory parameters for the repmgr daemon. This parameter tells the daemon if it should initiate an automatic failover when a failover situation is detected. It can have either of two values: “manual” or “automatic”. We will set this to automatic in each node:
failover='automatic'
promote_command
This is another mandatory parameter for the repmgr daemon. This parameter tells the repmgr daemon what command it should run to promote a standby. The value of this parameter will be typically the “repmgr standby promote” command, or the path to a shell script that calls the command. For our use case, we set this to the following in each node:
promote_command='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'
follow_command
This is the third mandatory parameter for the repmgr daemon. This parameter tells a standby node to follow the new primary. The repmgr daemon replaces the %n placeholder with the node ID of the new primary at run time:
follow_command='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'
priority
The priority parameter adds weight to a node’s eligibility to become a primary. Setting this parameter to a higher value gives a node greater eligibility to become the primary node. Also, setting this value to zero for a node will ensure the node is never promoted as primary.
In our use case, we have two standbys: PG-Node2 and PG-Node3. We want to promote PG-Node2 as the new primary when PG-Node1 goes offline, and PG-Node3 to follow PG-Node2 as its new primary. We set the parameter to the following values in the two standby nodes:
| Node Name | Parameter Setting |
| PG-Node2 | priority=60 |
| PG-Node3 | priority=40 |
monitor_interval_secs
This parameter tells the repmgr daemon how often (in number of seconds) it should check the availability of the upstream node. In our case, there is only one upstream node: the primary node. The default value is 2 seconds, but we will explicitly set this anyhow in each node:
monitor_interval_secs=2
connection_check_type
The connection_check_type parameter dictates the protocol repmgr daemon will use to reach out to the upstream node. This parameter can take three values:
- ping: repmgr uses the PQPing() method
- connection: repmgr tries to create a new connection to the upstream node
- query: repmgr tries to run a SQL query on the upstream node using the existing connection
Again, we will set this parameter to the default value of ping in each node:
connection_check_type='ping'
reconnect_attempts and reconnect_interval
When the primary becomes unavailable, the repmgr daemon in the standby nodes will try to reconnect to the primary for reconnect_attempts times. The default value for this parameter is 6. Between each reconnect attempt, it will wait for reconnect_interval seconds, which has a default value of 10. For demonstration purposes, we will use a short interval and fewer reconnect attempts. We set this parameter in every node:
reconnect_attempts=4 reconnect_interval=8
primary_visibility_consensus
When the primary becomes unavailable in a multi-node cluster, the standbys can consult each other to build a quorum about a failover. This is done by asking each standby about the time it last saw the primary. If a node’s last communication was very recent and later than the time the local node saw the primary, the local node assumes the primary is still available, and does not go ahead with a failover decision.
To enable this consensus model, the primary_visibility_consensus parameter needs to be set to “true” in each node – including the witness:
primary_visibility_consensus=true
standby_disconnect_on_failover
When the standby_disconnect_on_failover parameter is set to “true” in a standby node, the repmgr daemon will ensure its WAL receiver is disconnected from the primary and not receiving any WAL segments. It will also wait for the WAL receivers of other standby nodes to stop before making a failover decision. This parameter should be set to the same value in each node. We are setting this to “true”.
standby_disconnect_on_failover=true
Setting this parameter to true means every standby node has stopped receiving data from the primary as the failover happens. The process will have a delay of 5 seconds plus the time it takes the WAL receiver to stop before a failover decision is made. By default, the repmgr daemon will wait for 30 seconds to confirm all sibling nodes have stopped receiving WAL segments before the failover happens.
repmgrd_service_start_command and repmgrd_service_stop_command
These two parameters specify how to start and stop the repmgr daemon using the “repmgr daemon start” and “repmgr daemon stop” commands.
Basically, these two commands are wrappers around operating system commands for starting/stopping the service. The two parameter values map these commands to their OS-specific versions. We set these parameters to the following values in each node:
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgr12.service' repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgr12.service'
PostgreSQL Service Start/Stop/Restart Commands
As part of its operation, the repmgr daemon will often need to stop, start or restart the PostgreSQL service. To ensure this happens smoothly, it is best to specify the corresponding operating system commands as parameter values in the repmgr.conf file. We will set four parameters in each node for this purpose:
service_start_command='sudo /usr/bin/systemctl start postgresql-12.service' service_stop_command='sudo /usr/bin/systemctl stop postgresql-12.service' service_restart_command='sudo /usr/bin/systemctl restart postgresql-12.service' service_reload_command='sudo /usr/bin/systemctl reload postgresql-12.service'
monitoring_history
Setting the monitoring_history parameter to “yes” will ensure repmgr is saving its cluster monitoring data. We set this to “yes” in each node:
monitoring_history=yes
log_status_interval
We set the parameter in each node to specify how often the repmgr daemon will log a status message. In this case, we are setting this to every 60 seconds:
log_status_interval=60
Step 4: Starting the repmgr Daemon
With the parameters now set in the cluster and the witness node, we execute a dry run of the command to start the repmgr daemon. We test this in the primary node first, and then the two standby nodes, followed by the witness node. The command has to be executed as the postgres user:
[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-run
The output should look like this:
INFO: prerequisites for starting repmgrd met DETAIL: following command would be executed: sudo /usr/bin/systemctl start repmgr12.service
Next, we start the daemon in all four nodes:
[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
The output in each node should show the daemon has started:
NOTICE: executing: "sudo /usr/bin/systemctl start repmgr12.service"
NOTICE: repmgrd was successfully started
We can also check the service startup event from the primary or standby nodes:
[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event --event=repmgrd_start
The output should show the daemon is monitoring the connections:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+---------------+----+---------------------+------------------------------------------------------------------ 4 | PG-Node-Witness | repmgrd_start | t | 2020-02-05 11:37:31 | witness monitoring connection to primary node "PG-Node1" (ID: 1) 3 | PG-Node3 | repmgrd_start | t | 2020-02-05 11:37:24 | monitoring connection to upstream node "PG-Node1" (ID: 1) 2 | PG-Node2 | repmgrd_start | t | 2020-02-05 11:37:19 | monitoring connection to upstream node "PG-Node1" (ID: 1) 1 | PG-Node1 | repmgrd_start | t | 2020-02-05 11:37:14 | monitoring cluster primary "PG-Node1" (ID: 1)
Finally, we can check the daemon output from the syslog in any of the standbys:
# cat /var/log/messages | grep repmgr | less
Here is the output from PG-Node3:
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] connecting to database "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:24 PG-Node3 systemd[1]: repmgr12.service: Can't open PID file /run/repmgr/repmgrd-12.pid (yet?) after start: No such file or directory Feb 5 11:37:24 PG-Node3 repmgrd[2014]: INFO: set_repmgrd_pid(): provided pidfile is /run/repmgr/repmgrd-12.pid Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] starting monitoring of node "PG-Node3" (ID: 3) Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] monitoring connection to upstream node "PG-Node1" (ID: 1) Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [DETAIL] last monitoring statistics update was 2 seconds ago Feb 5 11:39:26 PG-Node3 repmgrd[2014]: [2020-02-05 11:39:26] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state … …
Checking the syslog in the primary node shows a different type of output:
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] connecting to database "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] starting monitoring of node "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] monitoring cluster primary "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node-Witness" (ID: 4) is not yet attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node3" (ID: 3) is attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node2" (ID: 2) is attached Feb 5 11:37:32 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:32] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:38:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:38:14] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state Feb 5 11:39:15 PG-Node1 repmgrd[2017]: [2020-02-05 11:39:15] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state … …
Step 5: Simulating a Failed Primary
Now we will simulate a failed primary by stopping the primary node (PG-Node1). From the shell prompt of the node, we run the following command:
# systemctl stop postgresql-12.service
The Failover Process
Once the process stops, we wait for about a minute or two, and then check the syslog file of PG-Node2. The following messages are shown. For clarity and simplicity, we have color-coded groups of messages and added whitespaces between lines:
… Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] checking state of node 1, 2 of 4 attempts Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] checking state of node 1, 3 of 4 attempts Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of node 1, 4 of 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to reconnect to node 1 after 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 86405000 milliseconds Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] wal receiver not running Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] WAL receiver disconnected on all sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] WAL receiver disconnected on all 2 sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] local node's last receive lsn: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node3" (ID: 3) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 3 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] last receive LSN for sibling node "PG-Node3" (ID: 3) is: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has same LSN as current candidate "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has lower priority (40) than current candidate "PG-Node2" (ID: 2) (60) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node-Witness" (ID: 4) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node-Witness" (ID: 4) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 4 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the last 4 seconds … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promotion candidate is "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 5000 ms Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] this node is the winner, will now promote itself and inform other nodes … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promoting standby to primary Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] promoting server "PG-Node2" (ID: 2) using pg_promote() Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] STANDBY PROMOTE successful Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [DETAIL] server "PG-Node2" (ID: 2) was successfully promoted to primary Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] 2 followers to notify Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node3" (ID: 3) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node-Witness" (ID: 4) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] switching to primary monitoring mode Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] monitoring cluster primary "PG-Node2" (ID: 2) Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:55:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:55:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state Feb 5 11:56:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:56:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state … …
There is a lot of information here, but let’s break down how the events have unfolded. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[postgres@PG-Node-Witness ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
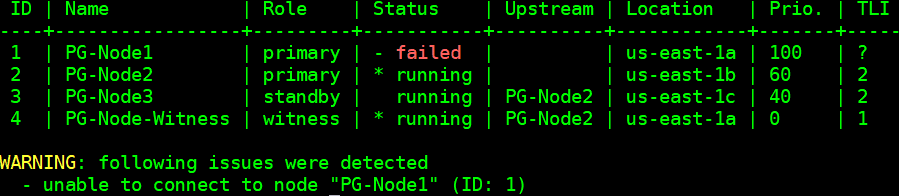
We can also look for the events by running the “repmgr cluster event” command:
[postgres@PG-Node2 ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------ 3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID: 2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID: 3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID: 4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID: 2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID: 2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID: 2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID: 4) has connected
Conclusion
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1

Hello
I configured my 3 nodes(primary, standby and witness). Cluster is configured what show screen:
https://www.dropbox.com/s/euvhdloeoiqu9yl/1.png?dl=0
but When I want start daemon repmgr i get error “ERROR: repmgrd does not appear to have started after 15 seconds” below screen
https://www.dropbox.com/s/p29fp2iigxqvca3/2.png?dl=0
why I can’t start daemon repmgr? Could someone help me in this topic, please? If You need all configuration, I may share with this.
Hi Lukasz,
Sorry to hear that you are seeing this error.
Your cluster configuration looks okay to me.
Two things you can do to troubleshoot:
– Run the daemon start command with the dry-run option. This will show you if the pre-requisites are met
– Look in the syslog file for repmgr daemon entries.
Hello.
After completing all the steps on PG-Node1, I ran ‘systemctl stop postgresql-12.service’
Then on PG-Node-Witness I ran “/ usr / pgsql-12 / bin / repmgr -f /etc/repmgr/12/repmgr.conf cluster show –compact”
The result is excellent!
Screenshot: https://yadi.sk/i/ocP8O6itZdiH7w
After that, on PG-Node1, I ran ‘systemctl start postgresql-12.service’, but PG-Node1 does not become ‘primary’ again. Why?
Screenshot: https://yadi.sk/i/pEwni2JlZ-bHkA
Thanks for your reply!
Hi Maksim,
Thanks for your query!
When one of the standby nodes is promoted to the primary role because the original primary has failed, you cannot bring back the original primary back into the cluster as a primary node – even if it can start its own PostgreSQL service.
This is because the promotion process does something called “fence off” to the original primary. The fence off process ensures the original primary cannot join the cluster as a primary. It is efectively segregated from the rest of the cluster.
This is to stop a “split-brain” situation – where a cluster has more than one primary. If you want to bring back the node to the cluster, you have to reinitialize it as a standby node. After that, you can promote it to primary role again (in that case, the promoted secondary which became primary will be fenced off again).
The reason you are seeing PG-Node1 in the output screenshot as “running” but with an exclamation mark is because repmgr recognizes it as a primary from its previous configuration, but it cannot see it as part of the cluster.
Hope this makes sense 🙂
Thank you very much for your reply )
Hello Sadequl;
Thank you, your tutorial and explanations are perfect.
I would appreciate it if you could answer my questions below.
1. I set an encrypted password for repmgr user. What is the best way to provide that password to ‘promote’ and ‘follow’ commands?
2. Is it possible to provide a bash script for ‘promote’ command? (i.e. to run both the follow command you provided and some others)
3. What if the witness node (or the connection) fails? How do daemons behave?
Thanks in advance.
Hi Suhan,
Thanks for your questions!
To answer your first question, you can perhaps think about using .pgpass file. This is what 2ndQuadrant recommends:
https://repmgr.org/docs/current/configuration-password-management.html#CONFIGURATION-PASSWORD-MANAGEMENT-OPTIONS
To answer the second question, yes it is possible to provide a bash script for the promote command, as I have mentioned in the article. The repmgr document also says the following:
“It is also possible to provide a shell script to e.g. perform user-defined tasks before promoting the current node. In this case the script must at some point execute repmgr standby promote to promote the node; if this is not done, repmgr metadata will not be updated and repmgr will no longer function reliably.”
https://repmgr.org/docs/current/repmgrd-basic-configuration.html
To answer the third question, if the witness is down and the primary is down, the standby nodes will understand the primary location is down. No node will promote itself, unless manually promoted. This is called a “degraded” operation mode. The repmgrd daemon will run, but wait indefinitely for the situation to be resolved.
You can refer to this link to understand about this mode:
https://repmgr.org/docs/repmgr.html#REPMGRD-DEGRADED-MONITORING
Hope this helps!
Hello Sadequl;
Many thanks for your quick answers.
Hello Sadequl,
my question is pretty similar Maxim’s.
let’s imagine that pg-node1 stopped works (long reboot, network problem any other things). Cluster performs autofailover. New master is pg-node2. but in 5 minutes pg-node1 is back. What would be the best way for application to choose right new primary node? (command repmgr -f /etc/repmgr/12/repmgr.conf node check –role will show both servers pg-node1 and pg-node2 as primary). Another words how to exclude two masters for application. This is not about repmgr in common, this is something about automatic failover for application.
Hi Valery,
Thanks for your question!
I believe what you will need for application-level failover is a connection pooling layer in front of the cluster. This was not covered in the article intentionally. Apps should connect to the cluster through a connection pooler like PGPool-II or PgBounder. With repmgr failing over to the standby, the old primary is fenced off, so it is no longer part of the cluster. Connections going to the PgBounder/PGPool-II don’t have to think about the underlying primary, because the connection pooler/load balancer will be automatically picking up the correct primary.
Another option for applications to choose the correct master is for it to run the “/usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show –compact” command periodically against the witness and parse the output. If the output shows the existing primary is in a failed state, it can dynamically change its connection string to the new primary. However, that’s a fairly involved mechanism to implement.
I hope this answers your query.
Sadequl,
Thank you so much for replay!
Thanks for the good explaination.
Leaves one important question for me: how to get the old primary back online and give it back the primary role ?
(I know how to get it online as a standby – but how to promote back ?)
Hi Enrico, thanks for your question!
To get the old primary back, you have to first bring it back as a standby to the cluster, and then do a failover again, this time manually. This will take the current primary out of the cluster, and will promote the newly added standby (i.e. the previous primary) as primary.
But bear in mind, there is no guarantee the newly added standby will be promoted as a primary if there are multiple standbys in the cluster, because the quorum may decide another standby should be promoted as the new primary – based on geographic proximity, priority etc. In such cases, you can add a higher priority for the newly added standby.
However, I would not recommend doing a manual failover simply to give the previous primary its primary role. That’s because any failover causes outage, and you want to eliminate or at least minimize outages. You do manual failover in only special cases: for example when repmgr is running in degraded mode and none of the standbys can be promoted to the primary role.
Hope this answers your question.
Hello Sadequl;
Thank you, your tutorial and explanations are perfect.
I would appreciate it if you could answer my questions below.
Then on PG-Node-Witness I ran “/ usr / pgsql-12 / bin / repmgr -f /etc/repmgr/12/repmgr.conf cluster show –compact”
The result is excellent!
After that, on PG-Node1, I ran ‘systemctl start postgresql-12.service’
My haproxy has a Master check to read / write. it saw 2 Masters. leading to data entry into the Master error. Is there any way that when PG-Node1 starts back and will automatically turn into standby or automatically destroy itself?
Hi Le Cong, thanks for your question!
There’s no automated way to turn the failed primary back to a standby node. However, the repmgr daemon can work with a connection pooling tool like PgBounder to fence off the failed primary so it doesn’t cause a split-brain scenario. This GitHub repo can help.
Also, pgBounder can work with HAProxy. This GitHub page can be useful in terms of showing how this is done.
Hope this helps!
Actually using PgBounder to fence off the failed primary is not a good solution. That article simply advises to reconfigure the pgbouncer from scratch.
There are other solutions like pacemaker/corosync with fence/stonith mechanism but they are just additional complexity for a two node setup. (they also bring their own problems with them)
I’m thinking to create a service/script on the witness node to monitor the events and take actions to stop the resurrected old primary bu using passwordless ssh.
(but I’m trying to find a way to cover possible up time of that resurrected primary)
On the other hand this sentence from the repmgr documentation is strange:
“… it can therefore promote itself (and ideally take action to fence the former primary).”
https://repmgr.org/docs/current/repmgrd-witness-server.html
ideally… I wish this was handled by repmgr without using any other tool. : )
Sadequl, If you allow me, I would like to propose a solution to the problem that a few people are talking about here.
Resurrected old master : )
1 | PG-Node1 | primary | * running
2 | PG-Node2 | primary | ! running
Finally I found a way to solve this problem without using any other tool other than repmgr.
By setting following three parameters, we can easily ‘fence’ the old primary.
child_nodes_connected_min_count = 1
child_nodes_connected_include_witness = ‘true’
child_nodes_disconnect_command = ‘sudo /usr/bin/systemctl stop postgresql-12.service’
By this way, we can simply keep the old primary down to investigate the problem.
Actually i’m using a custom bash script for both promote command and child_nodes_disconnect_command, so i can also assign and remove a floating virtual IP for the master. If you want, you can also write a much more clever script to rejoin the old primary as a standby.
Thanks, Suhan, for sharing :). Great stuff!!
Tried above implementation to fence off the primary but starting postgre service on old primary still shows the same status:
1 | PG-Node1 | primary | * running
2 | PG-Node2 | primary | ! running
Is there a working config file and script file sample that could be used for reference?
Hi Suhan,
Can you please share the custom script what you have used for automatic failover along with the floating IP.
Thanks in advance.
Regards,
Jitendra Yadav
Sorry guys; Krati and Jitendra…
I saw your reply after a long time.
Here is my script and the custom service:
*************************************
vi /usr/local/bin/pg_ha.sh:
#!/bin/bash
#——————————————————————————-
# STONITH script for the resurrected primary server.
#——————————————————————————-
witness=’postgres3.test.com’
VIP=’192.168.56.110′
nic=enp0s3
host=$(hostname)
while true
do
# If you can ping witness server, let’s begin.
/usr/bin/ping -q -c3 -w5 $witness > /dev/null 2>&1
if [ $? -eq 0 ]
then
# Ask witness server who is it following.
upstream=$(ssh $witness “/usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show” | grep witness | awk {‘print $10′})
# Do you see yourself as primary?
/usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf node check –role | grep primary > /dev/null 2>&1
if [ $? -eq 0 ]
then
# Then see if you can ping VIP.
/usr/bin/ping -q -c3 -w5 $VIP > /dev/null 2>&1
if ! [ $? -eq 0 ]
then
# You can’t ping, so, is witness following you?
/usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster crosscheck > /dev/null 2>&1
if [[ $host = $upstream || $? -eq 0 ]]
then
# Then you are the only primary, but the VIP address is not assigned yet, assign yourself and broadcast.
sudo /sbin/ip addr add $VIP/24 dev $nic label $nic:pg
sudo /usr/sbin/arping -b -A -c 3 -I $nic $VIP
fi
else
# If you can ping, do you ping yourself?
hostname -I | grep $VIP > /dev/null 2>&1
if ! [ $? -eq 0 ]
then
# Then VIP belongs to another node. Is witness server following someone else too?
if [ $host != $upstream ]
then
# Is the standby who should follow you missing too?
/usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf node check –downstream | grep missing > /dev/null 2>&1
if [ $? -eq 0 ]
then
# Then you’re definitely a zombie, pull the trigger !!!
sudo /sbin/ip addr del $VIP/24 dev $nic label $nic:pg
sudo /usr/bin/systemctl stop postgresql-12.service
fi
fi
fi
fi
else
# If you are not a primary, delete the VIP directly!
hostname -I | grep $VIP > /dev/null 2>&1
if [ $? -eq 0 ]
then
sudo /sbin/ip addr del $VIP/24 dev $nic label $nic:pg
fi
fi
fi
sleep 5
done
*************************************
*************************************
vi /etc/systemd/system/pg_ha.service:
[Unit]
Description=PostgreSQL Virtual-IP and STONITH service
After=network.target
After=repmgr12.service
[Service]
Type=simple
User=postgres
Group=postgres
ExecStart=’/usr/local/bin/pg_ha.sh’
Restart=on-failure
RestartSec=10
TimeoutSec=10
[Install]
WantedBy=multi-user.target
*************************************
Hi Suhan,
Thanks for the custom script. can you also share the details repmgr.conf file for all the pg and witness server.
Also were this script need to deploy ? Witness server or on all the PG server and WItness server.
Thanks in advance
Regards,
Jitendra
Hi All ,
i had setup the REPMGR and did stop the serivce on PRIMARY to siumulate automatic failover .
Post failover , STANDBY turned PRIMARY but OLD PRIMARY is not joining the cluster as STANDBY .
-bash-4.2$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show –compact
ID | Name | Role | Status | Upstream | Location | Prio. | TLI
—-+————————————–+———+———–+————————————–+———-+——-+—–
1 | qpass-dev-oracle12c-1.sea2.qpass.net | primary | * running | | default | 100 | 13
2 | qpass-dev-oracle12c-2.sea2.qpass.net | primary | – failed | ? | default | 100 |
3 | itek-uat-oracle-101.han2.qpass.net | witness | * running | qpass-dev-oracle12c-1.sea2.qpass.net | default | 0 | n/a
I had to run the NODE REJOIN command manually to get this OLD PRIMARY in the cluster as standby .
Is there any was i can achieve this automatically ?
Once i run the NODE REJOIN manually ,then OLD PRIMARY joins the cluster :
-bash-4.2$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show –compact
ID | Name | Role | Status | Upstream | Location | Prio. | TLI
—-+————————————–+———+———–+————————————–+———-+——-+—–
1 | qpass-dev-oracle12c-1.sea2.qpass.net | primary | * running | | default | 100 | 13
2 | qpass-dev-oracle12c-2.sea2.qpass.net | standby | running | qpass-dev-oracle12c-1.sea2.qpass.net | default | 100 | 12
3 | itek-uat-oracle-101.han2.qpass.net | witness | * running | qpass-dev-oracle12c-1.sea2.qpass.net | default | 0 | n/a
Please let me know if can do this automatically ?
Hi Deepak,
Thanks for your question. In the setup you are using, I can see there was one primary and one standby node. With this approach, a failover will automatically make repmgr choose the standby as the new master. If you want to use the old primary as a standby, you have to reinitialize it as the new standby. I do not think there is any simple way to automatically make a failed primary as a standby.
What this article shows though is when you have more than one standby, and one of the standbys is promoted to the primary role, repmgr will automatically make sure the remaining standbys are following the new primary.
Hoping you can assist or point me in the right direction.
Why isn’t the priority taken, I have set three different values in the repmgr.conf file but they all show at 100. I assume a a result they all want to be primary 🙂
[root@vmken-pgsql-node1 ~]# su – postgres -c ‘/usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show –compact’
ID | Name | Role | Status | Upstream | Location | Prio. | TLI
—-+———————+———+———————-+———————+———-+——-+—–
1 | vmken_pgsql_node1 | primary | * running | | default | 100 | 1
2 | vmken-pgsql-node2 | standby | ! running as primary | | default | 100 | 2
3 | vmlat-pgsql-node3 | standby | ! running as primary | | default | 100 | 3
4 | vmken-pgsql-witness | witness | * running | ! vmlat-pgsql-node3 | default | 0 | n/a
WARNING: following issues were detected
– node “vmken-pgsql-node2” (ID: 2) is registered as standby but running as primary
– node “vmlat-pgsql-node3” (ID: 3) is registered as standby but running as primary
– node “vmken-pgsql-witness” (ID: 4) reports a different upstream (reported: “vmlat-pgsql-node3”, expected “vmken_pgsql_node1”)
#1
node_id=1
node_name=’vmken_pgsql_node1′
conninfo=’host=192.168.24.185 user=repmgr$ dbname=repmgr connect_timeout=2′
data_directory=’/var/lib/pgsql/12/data’
failover=’automatic’
promote_command=’/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf –log-to-file’
follow_command=’/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf –log-to-file –upstream-node-id=%n’
priority=100
monitor_interval_secs=2
connection_check_type=’ping’
primary_visibility_consensus=true
standby_disconnect_on_failover=true
repmgrd_service_start_command=’sudo /usr/bin/systemctl start repmgr12.service’
repmgrd_service_stop_command=’sudo /usr/bin/systemctl stop repmgr12.service’
service_start_command=’sudo /usr/bin/systemctl start postgresql-12.service’
service_stop_command=’sudo /usr/bin/systemctl stop postgresql-12.service’
service_restart_command=’sudo /usr/bin/systemctl restart postgresql-12.service’
service_reload_command=’sudo /usr/bin/systemctl reload postgresql-12.service’
monitoring_history=yes
log_status_interval=60
#2:
node_id=2
node_name=’vmken-pgsql-node2′
conninfo=’host=192.168.24.186 user=repmgr$ dbname=repmgr connect_timeout=2′
data_directory=’/var/lib/pgsql/12/data’
failover=’automatic’
promote_command=’/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf –log-to-file’
follow_command=’/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf –log-to-file –upstream-node-id=%n’
priority=80
monitor_interval_secs=2
connection_check_type=’ping’
primary_visibility_consensus=true
standby_disconnect_on_failover=true
repmgrd_service_start_command=’sudo /usr/bin/systemctl start repmgr12.service’
repmgrd_service_stop_command=’sudo /usr/bin/systemctl stop repmgr12.service’
service_start_command=’sudo /usr/bin/systemctl start postgresql-12.service’
service_stop_command=’sudo /usr/bin/systemctl stop postgresql-12.service’
service_restart_command=’sudo /usr/bin/systemctl restart postgresql-12.service’
service_reload_command=’sudo /usr/bin/systemctl reload postgresql-12.service’
#3
node_id=3
node_name=’vmlat-pgsql-node3′
conninfo=’host=192.168.24.187 user=repmgr$ dbname=repmgr connect_timeout=2′
data_directory=’/var/lib/pgsql/12/data’
failover=’automatic’
promote_command=’/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf –log-to-file’
follow_command=’/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf –log-to-file –upstream-node-id=%n’
priority=60
monitor_interval_secs=2
connection_check_type=’ping’
primary_visibility_consensus=true
standby_disconnect_on_failover=true
repmgrd_service_start_command=’sudo /usr/bin/systemctl start repmgr12.service’
repmgrd_service_stop_command=’sudo /usr/bin/systemctl stop repmgr12.service’
service_start_command=’sudo /usr/bin/systemctl start postgresql-12.service’
service_stop_command=’sudo /usr/bin/systemctl stop postgresql-12.service’
service_restart_command=’sudo /usr/bin/systemctl restart postgresql-12.service’
service_reload_command=’sudo /usr/bin/systemctl reload postgresql-12.service’
monitoring_history=yes
log_status_interval=60
promote_command=’/etc/repmgr/12/promote.sh’
To add some more information
[root@vmken-pgsql-node1 ~]# su – postgres -c ‘/usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf node check –verbose’
NOTICE: using provided configuration file “/etc/repmgr/12/repmgr.conf”
WARNING: node “vmken-pgsql-node2” not found in “pg_stat_replication”
WARNING: node “vmlat-pgsql-node3” not found in “pg_stat_replication”
Node “vmken_pgsql_node1”:
Server role: OK (node is primary)
Replication lag: OK (N/A – node is primary)
WAL archiving: OK (0 pending archive ready files)
Upstream connection: OK (N/A – node is primary)
Downstream servers: CRITICAL (2 of 2 downstream nodes not attached; missing: vmken-pgsql-node2 (ID: 2), vmlat-pgsql-node3 (ID: 3))
Replication slots: OK (node has no physical replication slots)
Missing physical replication slots: OK (node has no missing physical replication slots)
Configured data directory: OK (configured “data_directory” is “/var/lib/pgsql/12/data”)
[root@vmken-pgsql-node1 ~]#
Hi Mike,
Sorry for th3e belated reply. From what I am seeing in the output you provided, the two standby nodes are definitely not synched with the primary. When you have an exclamation mark (!) in the “CLUSTER SHOW” command’s output against a standby server, it means the node is either not correctly configured or has missed WALs from the primary etc.
Also, if you see the node check command out, you can see this:
“CRITICAL (2 of 2 downstream nodes not attached; missing: vmken-pgsql-node2 (ID: 2), vmlat-pgsql-node3 (ID: 3))”
What I would suggest is this:
1. You stop the PostgreSQL service in both the standby nodes
2. You remove their data directories
3. You run standby clone to ensure they are synched with primary.
4. You start them and force attach them to the cluster.
5. Also try to restart the Witness node and see what it reports.
Hope it helps.
Hello Sadequl,
I am new to Postgres and exploring the various HA, Load Balancing, and failover options in Postgres.
The steps and information given are pretty much clear and meaningful, I have executed the steps and able to achieve the replication and failover configuration. I have below queries
1) Is the repmgr is used only for replication and failover? can I do the load balancing between my instances using the repmgr?
2) With the mentioned configuration always one node becomes active and we can execute read write query only to the primary node and not to the secondary node, is my understanding is correct?
3) The mentioned configuration is only HA and Failover and not the load balancing, is the understanding correct?
4) In my case when PGNode 1 failed then PGNode 3 became the primary and PGNode 2 upstream became PGNode 3, Is this random? as the priority is set as per the steps mentioned 40 for PGNode 2 and 60 for PG Node3
5) I execute scenario as PGNode1 failed –> PGNode 3 Became primary and PGNode upstream became PGNode 3, Then PGNode 3 failed –> PGNode 2 became primary and witness node upstream became PGNode 2, Then I started the PGNode1 and PGNode 3 and i am getting below output
[postgres@ip-172-31-32-177 ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show –compact
ID | Name | Role | Status | Upstream | Location | Prio. | TLI
—-+—————–+———+———–+———-+———-+——-+—–
1 | PG-Node1 | primary | ! running | | default | 100 | 1
2 | PG-Node2 | primary | * running | | default | 100 | 3
3 | PG-Node3 | primary | ! running | | default | 100 | 2
4 | PG-Node-Witness | witness | * running | PG-Node2 | default | 0 | n/a
WARNING: following issues were detected
– node “PG-Node1” (ID: 1) is running but the repmgr node record is inactive
– node “PG-Node3” (ID: 3) is running but the repmgr node record is inactive
I can see that all Nodes show role as primary, how can I make the others standby again? shall I reregister the rests as standby?
Hi Sandip,
Thanks for your comments! To answer your questions:
1 & 3. Yes, repmgr is a tool for setting up replication in an automated way. It also achieves HA by automating failovers and node promotions. It is not used for load balancing.
2. Yes with the setup shown, the primary node will be used for read/write operations and the standby nodes will be used for hosting replicated data. If you want to run reads against standbys and writes against primary – again you will have to use a load balancer.
4. I am not sure why the higher priority node did not become primary. Can you check the node priorities when the cluster is working (with PD-Node1 as master and PG-Node2 and PG-Node3 as standbys) by running the “cluster show” command? From the output you provided, I can see the priority for all nodes are 100. Unless that is showing the correct values, the higher priority node may not become primary.
5. In this case, once a standby is upgraded to primary, the previous primary is no longer recognized by repmgr as part of the cluster, even you restart it. However, its record is still in the repmgr metadata as a primary node, but repmgr marks it as inactive. You can see that although PG-Node1 and PG-Node3 are shown as “running”, their names are preceded by an exclamation mark (!). These show the nodes are no longer part of the cluster. You can reinitialize the replication to these nodes as standby, and for that, you have to stop the PostgreSQL in these nodes, remove their data directories, and follow the same steps to set them up as standbys. You can then force register these nodes, which will make repmgr recognize them as standbys.
Hope this helps 🙂
Dear Sadequl Hussain,
Thanks for your response, I have corrected the priorities and checked the replication and failover is working as expected.
Once the master node is failed the other stand by node becomes Primary, Can you please help me with how can i recover the master node again? either manually or do the automatic recovery using repmgr?
Also Can i use the repmgr for DR setup? how should be the architecture
Hi Sandip,
I am happy that the failover is now working and you have the issue sorted!
If you need to recover the master node (assuming you want that node to be part of the cluster again), you can recreate the replication to it as a standby.
repmgr is meant to be a HA solution, not a DR solution. A database HA solution like repmgr ensures the PostgreSQL instance is running and available for client connections if the primary node fails. A database DR solution on the other hand ensures you have backups of your database available for restoring when there’s a catastrophic failure – like unrecoverable data corruption, compromised security, site failure, etc. Having said this, 2ndQuadrant does offer a robust DR solution (once again free), called BARMAN (Backup and Recovery Manager). You can find more info about it here.
Hello Sadequl
What is the difference beetween commands standby switchover and standby switchover –siblings-follow ?
For automatic failover, SSH passwordless setup is required? why it is required for: standby switchover –siblings-follow ?
Hi Marcin,
The “standby switchover” command will promote a standby to primary and the existing primary to standby. The “standby switchover –siblings-follow” command will ensure other existing standbys connected to the node being demoted to follow the newly promoted primary. With an SSH passwordless connection, the repmgr daemon in different nodes cannot connect to other nodes seamlessly for promotion, demotion, and connecting to the new primary, etc.
These two links will help if you haven’t seen these already:
1. Performing a switchover with repmgr
2. repmgr standby switchover
Let me know if it answers your questions.
Thank you for response.
So… standby switchover –siblings-follow is for ensure that all standbys are connecting to new primary. Why it is not used by default?
It is possible to define other IP address (or DNS name) for specific postgresql server for SSH connections?
It is needed if connection via SSH is possible by other network interface than postgreSQL service
Hi Marcin,
Thanks for your comments.
I am not sure why the “-siblings” option isn’t used by default. Perhaps you can look at the repmgr documentation 🙂
I am not sure if I have understood you correctly for the next question. Assuming you are using Amazon Web Service EC2 instances for the PostgreSQL cluster, you can attach a second ENI (Elastic Network Interface) to the EC2 instance, and assign it a separate private IP.
Hope this answers your questions 🙂
Good time of the day, Mr. Sadequl Hussain!
I have read your manual. It’s super. Following your guide, I put together a cluster of two Postgresql nodes (Master and Slave) + Witness and it works well. But there are two questions:
1. After the witness has registered in the cluster, I enter the command “sudo -u postgres repmgr -f /etc/postgresql/12/main/repmgr.conf node check” and see the following line:
Upstream connection: CRITICAL (node “zabproxynode1” (ID: 3) is not attached to expected upstream node “zabservtstnode1” (ID: 1))
Note: zabproxynode1 is Witness, zabservtstnode1 is Master.
Is it correct?
2. After I removed the Slave from the cluster by entering the command: “repmgr standby unregister”, I rebooted Debian. But the demon repmgrd did not go into the ranny state.
Then I re-registered the Slave in the cluster. And I tried to set repmgrd with the command “repmgr daemon start”, but repmgrd did not go into the running state.
I could start repmgrd only with system commands: “systemctl stop repmgrd” and then “systemctl start repmgrd”.
Tell me why repmgrd does not start with a command “repmgr daemon start”?
Hi Sergey,
1. To answer your first question, it appears the witness node cannot connect to the master node for some reason (it needs to be able to co9nnect to all the nodes in the cluster). You may want to check if the primary node is allowing traffic from the witness node. You can start with a simple “ping” command from the witness to see if the master is reachable, and then if that works, you can check the pg_hba.conf file of the primary node to see if it has an entry that allows traffic from the witness.
2. To answer your second question, the repmgr daemon uses its own database to check the status of the cluster. When you had re-registered the standby node, it updated the internal database with a separate set of metadata than the ones it used before (when the standby was registered the first time). It may be (and I am guessing here) the old metadata was still marked as current for some reason, and repmgr daemon could not be started by the native command. However, the systemd command would not use the internal metadata, so it could load the executable process in memory and show it as running.
The other reason I can think of (and it may the actual case here) is that the native daemon would not start if it saw the node was not properly initialized as a standby. When you take a node away from a cluster, the recommended way to bring it back online is to reinitialize the replication from the primary, and then register it with the repmgr command.
You may also want to check the repmgr logs (if you haven’t done already) to see what message the native daemon command was logging when it failed to start.
Hope this helps!
Good day, Mr. Sadekul Hussein!
Thanks for your reply. Sorry I didn’t answer for a long time.
On my question #1, I would like to inform you that this situation manifested itself on the repmgr version 5.1.0. After updating repmgr to 5.2.0, this problem is resolved. The Witness Site Verification Report now contains the correct information:
# sudo -u postgres repmgr -f /etc/postgresql/12/main/repmgr.conf node check
…
Upstream connection: OK (N/A – node is a witness)
…
Previously there was the following information:
Upstream connection: CRITICAL (node “zabproxynode1” (ID: 3) is not attached to expected upstream node “zabservtstnode1” (ID: 1))
And in my opinion it was incorrect, because this is a Witness, not a Standby
On my question #2, I inform you that I was not able to check again this problem in repmgr on version 5.1.0. And I checked it already on version 5.2.0. But after performing the replication of the Slave from the Master. And the problem is solved.
Thanks again for your answers.
All the best!
thank you for that amazing article and for sharing the knowledge,
but I want to know after making the replication and in case of failover, and the standby server now became the primary
now if I am using an application that connected that the primary DB
how to inform the application to use the standby node not the main, how to connect to the cluster, not the DB itself.
I cannot understand this point could you please help me with that, if so please can you advise me with an article to do so
Hi Ahmed,
repmgr does not take care of the repointing of the application to the new primary instance. It’s a replication management system. For repointing the application, you can use something like HAProxy in front of the cluster to take care of application transparency.
hi, before I try to implement this configuration, there is one thing I want to confirm. does node witness act as a load balancer too? I mean we do a query to the witness node, then does the witness node who shares the query point to the main node if it is a write query?
Hi Vikri,
No, the witness node is only used to arbitrate the replication failover when a primary node becomes unavailable. The type of write-traffic redirection you mentioned is done by a load balancer like HAProxy or PGPool. Hope this helps!
Hi Vikri!
I have an issue as bellow
I run: repmgr -f /etc/repmgr.conf daemon start
ERROR:
NOTICE: executing: “sudo /usr/bin/systemctl start repmgrd”
ERROR: repmgrd does not appear to have started after 15 seconds
HINT: use “repmgr service status” to confirm that repmgrd was successfully started
and I also check : repmgr service status
and I also get:
ID | Name | Role | Status | Upstream | repmgrd | PID | Paused? | Upstream last seen
—-+————–+———+———–+———-+————-+—–+———+——————–
1 | node1 | primary | * running | | not running | n/a | n/a | n/a
2 | node2 | standby | running | node1 | not running | n/a | n/a | n/a
3 | node3 | standby | running | node1 | not running | n/a | n/a | n/a
4 | node-witness | witness | * running | node1 | not running | n/a | n/a | n/a
could you help me resolve that?
Hi NghiepVo,
Obviously, the repmgrd services are not starting due to some error. It’s hard to troubleshoot from a simple error message. Did you check the remgrd log? Does the log file give any indication?
We are also facing the same issue dameon service is not getting started in our case as well.
We have CentOS7.9
Setup Info:
ID | Name | Role | Status | Upstream | Location | Prio. | TLI
—-+—————–+———+———–+———-+———-+——-+—–
1 | PG-Node1 | primary | * running | | default | 100 | 1
2 | PG-Node2 | standby | running |PG-Node1 | default | 100 | 3
3 | PG-Node-Witness | witness | * running | PG-Node1 | default | 0 | n/a
Command failed to executed: /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
Error: repmgrd: [2021-03-12 18:59:55] [ERROR] could not open the PIF file /run/repmgr/repmgrd-12.pid
systemd : Can;t open the PID file /run/repmgrd-12.pid (yet?) after start : No such file or directory
systemd : Daemon never wrote its PID file. Failing.
systemd : Failed to start A replication manager, and failover management tool for PostgreSQL,
systemd : Uint repmgr12.service entered failed state.
systemd : repmgr12.service failed.
Hi Sadequl,
Need your help here.
Hi NghiepVo
Have you find any solution here ?
Hi Sadequl,
I have setup the postgress replication same as mentioned by you, PFB my setup information.
ID | Name | Role | Status | Upstream | Location | Prio. | TLI
—-+—————–+———+———–+———-+———-+——-+—–
1 | PG-Node1 | primary | * running | | default | 100 | 1
2 | PG-Node2 | standby | running |PG-Node1 | default | 100 | 3
3 | PG-Node-Witness | witness | * running | PG-Node1 | default | 0 | n/a
I am not able to start the dameon service now, below command is giving me the error.
Command: /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
Error: repmgrd: [2021-03-12 18:59:55] [ERROR] could not open the PIF file /run/repmgr/repmgrd-12.pid
systemd : Can;t open the PID file /run/repmgrd-12.pid (yet?) after start : No such file or directory
systemd : Daemon never wrote its PID file. Failing.
systemd : Failed to start A replication manager, and failover management tool for PostgreSQL,
systemd : Uint repmgr12.service entered failed state.
systemd : repmgr12.service failed.
Dry run command to start the daemon executed successfully.
Need you assistance here.
We have used CentOS 7.9 OS.
Hi Sadequl,
Thank you for this detailed guide which I learn a lot from it. I follow each step but I’m facing 2 problems:
1- I can’t start repmgrd on the slave nodes – the replication still working fine
2- the failover scenario gives me the following:
WARNING: following issues were detected
– unable to connect to node “pg-primary” (ID: 1)
– node “pg-primary” (ID: 1) is registered as an active primary but is unreachable
– unable to connect to node “pg-slave1” (ID: 2)’s upstream node “pg-primary” (ID: 1)
– unable to determine if node “pg-slave1” (ID: 2) is attached to its upstream node “pg-primary” (ID: 1)
– unable to connect to node “witness” (ID: 10)’s upstream node “pg-primary” (ID: 1)
and the standby node is not elected to primary
Hi Sadequl,
thank you for this great guidelines, it saved a lot of effort and time, I follow each step but actually i don’t know what’s the problem. the replication is working fine but the automatic failover doesn’t promote the standby machine to be primary however when I run the command manually it promotes the next standby and ready machine, I appreciate your help
before failover:
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
—-+————+———+———–+————+———-+———-+———-+—————————————————————-
1 | pg-primary | primary | * running | | default | 100 | 1 | host=10.110.30.101 user=repmgr dbname=repmgr connect_timeout=2
2 | pg-slave1 | standby | running | pg-primary | default | 100 | 1 | host=10.110.30.102 user=repmgr dbname=repmgr connect_timeout=2
3 | pg-slave2 | standby | running | pg-primary | default | 40 | 1 | host=10.110.30.103 user=repmgr dbname=repmgr connect_timeout=2
10 | witness | witness | * running | pg-primary | default | 0 | n/a | host=10.110.30.100 user=repmgr dbname=repmgr connect_timeout=2
after failover:
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
—-+————+———+—————+————–+———-+———-+———-+—————————————————————-
1 | pg-primary | primary | ? unreachable | ? | default | 100 | | host=10.110.30.101 user=repmgr dbname=repmgr connect_timeout=2
2 | pg-slave1 | standby | running | ? pg-primary | default | 100 | 1 | host=10.110.30.102 user=repmgr dbname=repmgr connect_timeout=2
3 | pg-slave2 | standby | running | ? pg-primary | default | 40 | 1 | host=10.110.30.103 user=repmgr dbname=repmgr connect_timeout=2
10 | witness | witness | * running | ? pg-primary | default | 0 | n/a | host=10.110.30.100 user=repmgr dbname=repmgr connect_timeout=2
WARNING: following issues were detected
– unable to connect to node “pg-primary” (ID: 1)
– node “pg-primary” (ID: 1) is registered as an active primary but is unreachable
– unable to connect to node “pg-slave1” (ID: 2)’s upstream node “pg-primary” (ID: 1)
– unable to determine if node “pg-slave1” (ID: 2) is attached to its upstream node “pg-primary” (ID: 1)
– unable to connect to node “pg-slave2” (ID: 3)’s upstream node “pg-primary” (ID: 1)
– unable to determine if node “pg-slave2” (ID: 3) is attached to its upstream node “pg-primary” (ID: 1)
– unable to connect to node “witness” (ID: 10)’s upstream node “pg-primary” (ID: 1)
Hi, I have configured postgres cluster using repmgr and pgpool, now facing below issue:
ID | Name | Role | Status | Upstream | Location | Prio. | TLI
—-+————+———+———————-+———-+———-+——-+—–
1 | PG-NODE1 | primary | ! running | | default | 100 | 13
2 | PG-NODE2 | primary | ! running as standby | | default | 60 | 13
3 | PG-NODE3 | standby | running | PG-NODE1 | default | 40 | 13
4 | PG-WITNESS | witness | * running | PG-NODE2 | default | 0 | n/a
WARNING: following issues were detected
– node “PG-NODE1” (ID: 1) is running but the repmgr node record is inactive
– node “PG-NODE2” (ID: 2) is registered as primary but running as standby
Can you please let me know to fix this.
Thanks.
Hi,
Hope you are doing great.
I have an issue as stated below, please assist me on this:
Output from witness node:(PG-WITNESS)
ID | Name | Role | Status | Upstream | Location | Prio. | TLI
—-+————+———+———————-+———-+———-+——-+—–
1 | PG-NODE1 | primary | ! running | | default | 100 | 13
2 | PG-NODE2 | primary | ! running as standby | | default | 60 | 13
3 | PG-NODE3 | standby | running | PG-NODE1 | default | 40 | 13
4 | PG-WITNESS | witness | * running | PG-NODE2 | default | 0 | n/a
WARNING: following issues were detected
– node “PG-NODE1” (ID: 1) is running but the repmgr node record is inactive
– node “PG-NODE2” (ID: 2) is registered as primary but running as standby
Output from master Node:(PG-NODE1)
ID | Name | Role | Status | Upstream | Location | Prio. | TLI
—-+————+———+———–+————+———-+——-+—–
1 | PG-NODE1 | primary | * running | | default | 100 | 13
2 | PG-NODE2 | standby | running | PG-NODE1 | default | 60 | 13
3 | PG-NODE3 | standby | running | PG-NODE1 | default | 40 | 13
4 | PG-WITNESS | witness | * running | ! PG-NODE2 | default | 0 | n/a
WARNING: following issues were detected
– node “PG-WITNESS” (ID: 4) reports a different upstream (reported: “PG-NODE2”, expected “PG-NODE1”)
Output from Standby node-1:(PG-NODE2)
ID | Name | Role | Status | Upstream | Location | Prio. | TLI
—-+————+———+———–+————+———-+——-+—–
1 | PG-NODE1 | primary | * running | | default | 100 | 13
2 | PG-NODE2 | standby | running | PG-NODE1 | default | 60 | 13
3 | PG-NODE3 | standby | running | PG-NODE1 | default | 40 | 13
4 | PG-WITNESS | witness | * running | ! PG-NODE2 | default | 0 | n/a
WARNING: following issues were detected
– node “PG-WITNESS” (ID: 4) reports a different upstream (reported: “PG-NODE2”, expected “PG-NODE1”)
So can we simply un-register witness node and register it again to resolve this or something else is required.
Thanks.
Hi All,
I had implement replication with repmgr with 1 primary and 2 standby and 1 witness server.
ID | Name | Role | Status | Upstream | Location | Prio. | TLI
—–+——————-+———+———–+———————+———-+——-+—–
100 | WitnessDB_AFCS | witness | * running | PrimaryDB_AFCS_DC | default | 0 | n/a
301 | Standby_AFCS_HA | standby | running | PrimaryDB_AFCS_DC | default | 0 | 12
701 | PrimaryDB_AFCS_DC | primary | * running | | default | 100 | 12
801 | Standby_AFCS_DR | standby | running | ! PrimaryDB_AFCS_DC | default | 100 | 12
After disconnecting the standby server I could not rejoin the standby server.
due to Big database size not feasible to me, standby clone from scratch every time
bash-4.2$ /usr/pgsql-12/bin/repmgr node rejoin -f /var/lib/pgsql/repmgr.conf -d ‘$primary_conninfo’ –force-rewind –config-files=pg_hba.conf,postgresql.conf –verbose
NOTICE: using provided configuration file “/var/lib/pgsql/repmgr.conf”
INFO: timelines are same, this server is not ahead
DETAIL: local node lsn is 1C/A005650, rejoin target lsn is 1C/16005E30
INFO: prerequisites for using pg_rewind are met
INFO: 2 files copied to “/tmp/repmgr-config-archive-Standby_AFCS_DR”
NOTICE: executing pg_rewind
DETAIL: pg_rewind command is “/usr/pgsql-12/bin/pg_rewind -D ‘/data/PG_DATA’ –source-server=’ $primary_conninfo'”
NOTICE: 2 files copied to /data/PG_DATA
INFO: directory “/tmp/repmgr-config-archive-Standby_AFCS_DR” deleted
NOTICE: setting node 801’s upstream to node 701
WARNING: unable to ping “$primary_conninfo”
DETAIL: PQping() returned “PQPING_NO_RESPONSE”
NOTICE: starting server using “sudo /usr/bin/systemctl start postgresql-12.service”
INFO: node “Standby_AFCS_DR” (ID: 801) is pingable
WARNING: node “Standby_AFCS_DR” not found in “pg_stat_replication”
INFO: waiting for node “Standby_AFCS_DR” (ID: 801) to connect to new primary; 1 of max 60 attempts (parameter “node_rejoin_timeout”)
DETAIL: checking for record in node “PrimaryDB_AFCS_DC”‘s “pg_stat_replication” table where “application_name” is “Standby_AFCS_DR”
WARNING: node “Standby_AFCS_DR” not found in “pg_stat_replication”
WARNING: node “Standby_AFCS_DR” not found in “pg_stat_replication”
WARNING: node “Standby_AFCS_DR” not found in “pg_stat_replication”
WARNING: node “Standby_AFCS_DR” not found in “pg_stat_replication”
WARNING: node “Standby_AFCS_DR” not found in “pg_stat_replication”
INFO: waiting for node “Standby_AFCS_DR” (ID: 801) to connect to new primary; 6 of max 60 attempts (parameter “node_rejoin_timeout”)
DETAIL: checking for record in node “PrimaryDB_AFCS_DC”‘s “pg_stat_replication” table where “application_name” is “Standby_AFCS_DR”
WARNING: node “Standby_AFCS_DR” not found in “pg_stat_replication”
WARNING: node “Standby_AFCS_DR” not found in “pg_stat_replication”
WARNING: node “Standby_AFCS_DR” not found in “pg_stat_replication”
WARNING: node “Standby_AFCS_DR” not found in “pg_stat_replication”
WARNING: node “Standby_AFCS_DR” not found in “pg_stat_replication”
ERROR: NODE REJOIN failed
DETAIL: no active record for local node “Standby_AFCS_DR” found in node “PrimaryDB_AFCS_DC”‘s “pg_stat_replication” table
HINT: check the PostgreSQL log on the local node
Please help us to solve this issue in an efficient way.