
Geo-redundancy of PostgreSQL database backups with Barman
Barman 2.6 introduces support for geo-redundancy, meaning that Barman can now copy from another Barman instance, not just a PostgreSQL database.
Geographic redundancy (or simply geo-redundancy) is a property of a system that replicates data from one site (primary) to a geographically distant location as redundancy, in case the primary system becomes inaccessible or is lost. From version 2.6, it is possible to configure Barman so that the primary source of backups for a server can also be another Barman instance, not just a PostgreSQL database server as before.
![]()
Briefly, you can define a server in your Barman instance (passive, according to the new Barman lingo), and map it to a server defined in another Barman instance (primary).
All you need is an SSH connection between the Barman user in the primary server and the passive one. Barman will then use the rsync copy method to synchronise itself with the origin server, copying both backups and related WAL files, in an asynchronous way. Because Barman shares the same rsync method, geo-redundancy can benefit from key features such as parallel copy and network compression. Incremental backup will be included in future releases.
Geo-redundancy is based on just one configuration option: primary_ssh_command.
Our existing scenario
To explain how geo-redundancy works, we will use the following example scenario. We keep it very simple for now.
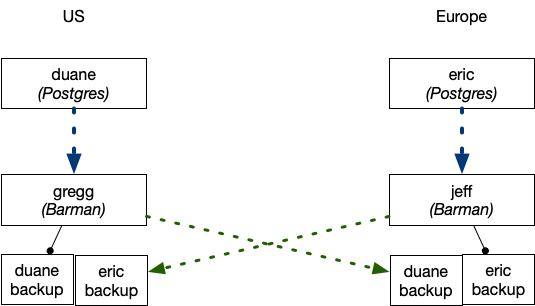
We have two identical data centres, one in Europe and one in the US, each with a PostgreSQL database server and a Barman server:
- Europe:
- PostgreSQL server:
eric - Barman server:
jeff, backing up the database server hosted oneric
- PostgreSQL server:
- US:
- PostgreSQL server:
duane - Barman server:
gregg, backing up the database server hosted onduane
- PostgreSQL server:
Let’s have a look at how jeff is configured to backup eric, by reading the content of the /etc/barman.d/eric.conf file:
[eric]
description = Main European PostgreSQL server 'Eric'
conninfo = user=barman-jeff dbname=postgres host=eric
ssh_command = ssh postgres@eric
backup_method = rsync
parallel_jobs = 4
retention_policy = RECOVERY WINDOW OF 2 WEEKS
last_backup_maximum_age = 8 DAYS
archiver = on
streaming_archiver = true
slot_name = barman_streaming_jeffFor the sake of simplicity, we skip the configuration of duane in gregg server as it is identical to eric’s in jeff.
Let’s assume that we have had this configuration in production for a few years (this goes beyond the scope of this article indeed).

Now Barman 2.6 is out, we have just updated our systems, and we can finally try and add geo-redundancy in the system.
Adding geo-redundancy
We now have the European Barman that backups up the European PostgreSQL server and the US Barman copying the US PostgreSQL server. Let’s now tell our Barman servers to relay their backups on the other, with a higher retention policy.
As a first step, we need to exchange SSH keys between the barman users (you can find more information about this process on Barman documentation).
We also need to make sure that compression method is the same between the two systems (this is typically set as a global option in the /etc/barman.conf file).
Let’s now proceed by defining duane as a passive server in Barman installed on jeff. Create a file called /etc/barman.d/duane.conf with the following content:
[duane]
description = Relay of main US PostgreSQL server 'Duane'
primary_ssh_command = ssh gregg
retention_policy = RECOVERY WINDOW OF 1 MONTHAs you may have noticed, we declare a longer retention policy in the redundant site (one month instead of two weeks).
If you type barman list-server, you will get something similar to:
duane - Relay of main US PostgreSQL server 'Duane' (Passive)
eric - Main European PostgreSQL server 'Eric'The cron command is responsible for synchronising backups and WAL files. This happens by transparently invoking two commands: sync-backup and sync-wals, which both rely on another command called sync-info (used to poll information from the remote server). If you have installed Barman as a package from 2ndQuadrant public RPM/APT repositories, barman cron will be invoked every minute.
The Barman installation on jeff will now check its catalogue for the duane server with the Barman instance installed on gregg, first copying the backup files (from the most recent one) and then the related WAL files.
One peek at the logs should unveil that Barman has started to synchronise its content with the origin one. To verify that backups are being relayed, type:
When a passive Barman server is copying from the primary Barman, you will see an output like this:
When the synchronisation is completed, you will see the familiar output of the list-backup command:
You can now do the same for the eric server on the gregg Barman instance. Create a file called /etc/barman.d/eric.conf on gregg with the following content:
[eric]
description = Relay of main European PostgreSQL server 'Eric'
primary_ssh_command = ssh jeff
retention_policy = RECOVERY WINDOW OF 1 MONTHThe diagram below depicts the architecture that we have been able to implement via Barman’s geo-redundancy feature:
What’s more
The above scenario can be enhanced by adding a standby server in the same data centre, and/or in the remote one, as well as by making use of the get-wal feature through barman-wal-restore.
The geo-redundancy feature increases the flexibility of Barman for disaster recovery of PostgreSQL databases, with better recovery point objectives and business continuity effectiveness at lower costs.
Should one of your Barman servers go down, you have another copy of your backup data that you can use for disaster recovery – of course with a slightly higher RPO (recovery point objective).
“The Barman installation on jeff will now check its catalogue for the duane server with the Barman instance installed on gregg, first copying the backup files (from the most recent one) and then the related WAL files.”
I’ve setup a barman to barman passive replication. As far as I can see in barman log, replication is started form older bakcup not newer.
Is something wrong in my configuration?
Hi Gabriele,
So as I understand, this feature creates one additional copy of the backup on the Europe site and that additional copy is sourced (not from the remote US server) but from the remote US backup, correct?
Thanks