
PG Phriday: BDR Around the Globe
With the addition of logical replication in Postgres 10, it’s natural to ask “what’s next”? Though not directly supported yet, would it be possible to subscribe two Postgres 10 nodes to each other? What kind of future would that be, and what kind of scenarios would be ideal for such an arrangement?
As it turns out, we already have a kind of answer thanks to the latency inherent to the speed of light: locality. If we can provide a local database node for every physical app location, we also reduce latency by multiple orders of magnitude.
Let’s explore the niche BDR was designed to fill.
What is Postgres-BDR?
Postgres-BDR is simply short for Postgres Bi-Directional Replication. Believe it or not, that’s all it needs to be. The implications of the name itself are numerous once fully explored, and we’ll be doing plenty of that.
So what does it do?
- Logical replication
- Multi-Master
- Basic conflict resolution (last update wins)
- Distributed locking
- Global sequences
- High latency replay (imagine a node leaves and comes back later)
The key to having Multi-Master and associated functionality is logical replication. Once we can attach to the logical replication stream, we just need a piece of software to communicate between all participating nodes to consume those streams. This is necessary to prevent nodes from re-transmitting rows received from another system and resolve basic conflicts.
Why Geographical Distribution?
Specifically:
- Local database instances
- Inter-node communication is high latency
- Eventual consistency is the only consistency (for now)
- That’s a Good Thing!(tm)
We don’t want latency between our application and the database, so it’s better to operate locally. This moves the latency into the back-end between the database nodes, and that means the dreaded “eventual consistency” model. It’s a natural consequence, but we can use it to our advantage.
Consider This
We have an application stack that operates in four locations: Sydney, Dubai, Dallas, and Tokyo.
We tried to get a data center in Antarctica, but the penguins kept going on strike. Despite that, here’s a look at average latencies between those locations:
| Dallas | Dubai | Sydney | Tokyo | |
|---|---|---|---|---|
| Dallas | xxx | 230ms | 205ms | 145ms |
| Dubai | 230ms | xxx | 445ms | 145ms |
| Sydney | 200ms | 445ms | xxx | 195ms |
| Tokyo | 145ms | 145ms | 195ms | xxx |
Based on the lag, Tokyo seems to be something of a centralized location. Still, those round-trip-times are awful.
Eww, Math
Imagine our initial database is in Dubai.
Say we start in Dubai and want to expand to the US at first. We may be tempted to simply spin up an AWS or Google Cloud instance or two running our application. But like all modern websites, we make liberal use of AJAX and each page contains multiple database-backed components. Even five simple queries could drastically bloat page load time and drive away potential customers.
That’s bad, m’kay? This is hardly a new problem, and there are several existing solutions:
- Front-end caching
- Problems with extremely dynamic content.
- Writes still need to go to Dubai.
- Back-end caching
- Only works for small-medium size datasets
- Writes still need to go to Dubai.
- Database replica
- Writes still need to go to Dubai.
We could use something like Varnish to cache the pages themselves, and that works for a few cases where there isn’t a lot of dynamic or user-generated content. Or if there is, we better have a lot of cache storage. Hopefully we don’t have any pages that need to write data, because that still has to go back to Dubai.
Alternatively, we could use memchached, Cassandra, or some other intermediate layer the application can populate and interact with instead. This is better, but can get stale depending on how we refresh these caches. Some of these cache layers can even capture writes locally and persist by committing to the primary store… in Dubai. This makes for great interactivity with potential implications regarding data consistency.
And then there’s outright Postgres streaming replicas. This is much closer to ideal for highly dynamic content, barring any unexpected network interruptions. And as usual, writes must be made in Dubai.
Yet all three of these solutions suffer from the same downfall.
Broken Record
All those darn writes being rerouted to Dubai. Writes always need to end up in the primary database, and this is where BDR comes in.
If our primary database is in Dubai, all our writes must eventually make it there, one way or another. Then it must propagate through all of our caching layers and replicas before it’s considered committed by the end user.
Or we can remove the Middle Man with BDR. In order to do that, we want a situation where all writes are local to their region. Something like this:
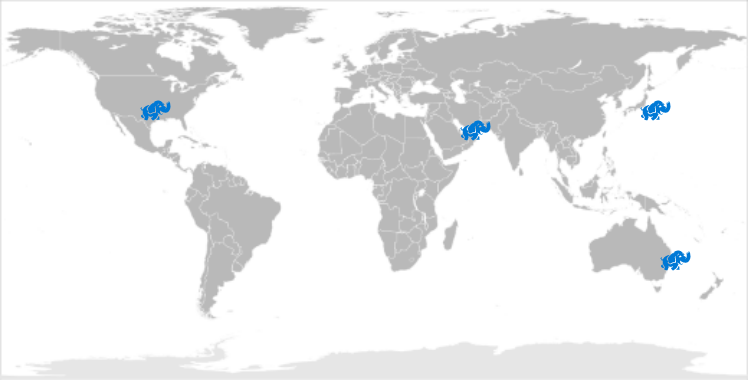
With BDR, we still have a “master” copy in every case, but it’s not integral to basic operation.
How do we Get There?
- Identify problem areas
- Find all sequence usage
- Isolate conflict scenarios
- Install BDR
- Create and subscribe
Now we get to the nitty-gritty. We need to start by making sure our sequences don’t clobber each other between the regions. Then we should consider all the ways interactions between regions might conflict. This may require a careful and time-consuming audit of the application stack, but it’s better than being surprised later.
Then we can work on deploying everything. Believe it or not, that’s probably the easiest part.
Seeking Sequences
We start our adventure by finding any serial columns that increment by using the Postgres nextval() function. BDR has a mechanism for ensuring sequence values never collide across the cluster, but we must first identify all sequences that are associated with a column that isn’t already a BIGINT. A query like this might work:
SELECT table_schema, table_name, column_name
FROM information_schema.columns
WHERE column_default LIKE 'nextval\(%'
AND data_type != 'bigint';
BDR’s built-in global sequence functionality needs BIGINT columns because it uses a lot of bit-shift math and packs it into a 64-bit integer. The sequence is no longer sequential, but it’s unique for up to 8-million values per second, per node.
Conflict Avoidance
The best way to prevent conflicts is to avoid them outright. Aggregate columns like “total” or “sum” are potential hot-spots for conflicting updates. If such a column must be used, consider constructing it from a ledger or event log instead. This way it doesn’t matter if Sydney adds 100 to a balance, and Texas adds 50, because each event is atomic.
Once applications can, they should interact with data specific to their region whenever possible. The less cross-talk between different regions, the less potential there is for conflict. If we scale down slightly, we can even consider this within a single datacenter. The goal is to separate write targets by using sticky sessions, natural hashes, assigned application zones, and so on.
Similarly, even if a session is operating outside of its region, conflicts can be avoided if the application doesn’t switch back and forth. If an application can’t “see” multiple copies of the database at alternating times, it’s much less likely to generate a conflicting row due to latency mismatches.
Off to the Races
Why are stored aggregates bad? Race conditions. Consider this scenario on a simple account table with a balance column.
- Sydney adds 50 to 100 balance
- Tokyo adds 50 to 100 balance
- Result should be 200, but is 150 instead due to latency
- Ledger of credit / debit would always be correct
- Think of a cash register receipt
- Use materialized aggregates for reports or summaries
Going into more detail helps illustrate what kinds of conflicts we want to prevent. A ledger has no concept of sum, just plus or minus. It’s possible to refund specific line-items so the full history is maintained. We can also generate the summary for all rows in the grouping. If a historical row is temporarily missing on a remote node, transient summaries may temporarily vary, but the incorrect balance will never exist as actual data.
These kinds of modifications are the safest approach, but are not always necessary in isolated cases. This is why it’s important to evaluate first.
Shop S-Mart
Local database; local writes. This is important and comes in two flavors:
- Tokyo operates on Tokyo data; Texas on Texas
- Update conflicts less likely
- Fewer / no race conditions
- Dubai operates in Dubai; Sydney in Sydney
- Prevents cross-data center conflicts
- Local writes are faster anyway
Since every BDR node has a copy of the full database, we could theoretically operate outside of our region. Of course, it’s better if we don’t. If Tokyo operates on a row from Texas, there’s a good chance Texas will overwrite that change or cause a conflict. We can avoid a non-deterministic result by keeping regional operations together.
Alternatively, the application may be configured in Sydney and try to operate on Sydney rows in the Dubai data center. That’s fine until other Sydney nodes are simultaneously connected to the database in Sydney. Unless there’s a very good reason for this, it’s probably a bad idea. It’s slower, defeats the purpose of geographical database distribution in general, and is almost guaranteed to generate conflicts.
Of course, if one region must be offline for maintenance or other purposes, using another geographical database is encouraged. Though even then, since we’re talking about continental divides, it’s probably better to have multiple local alternatives instead.
Journey of 1000 Miles
Assuming we have an existing cluster, how do we distribute to new zones? Let’s start with a basic arbitrary table from a corporate ordering system.
CREATE TABLE system_order (
order_id SERIAL PRIMARY KEY,
product_id INT NOT NULL,
customer_id INT NOT NULL,
unit_count INT NOT NULL,
status VARCHAR NOT NULL DEFAULT 'pending',
reading_date TIMESTAMPTZ NOT NULL DEFAULT now()
);
CREATE INDEX idx_system_order_product_id ON system_order (unit_count);
CREATE INDEX idx_system_order_reading_date ON system_order (reading_date);
Take note of the SERIAL primary key, which corresponds to the underlying INT type. It’s an easy mistake if values aren’t expected to exceed 2-billion, but such isn’t compatible with BDR global sequences. A script like this might work for converting the existing tables before adding BDR to the mix:
COPY (
SELECT 'ALTER TABLE ' || table_schema || '.' || table_name ||
' ALTER COLUMN ' || column_name || ' TYPE BIGINT;'
FROM information_schema.columns
WHERE column_default LIKE 'nextval\(%'
AND data_type != 'bigint'
) TO '/tmp/alter_columns.sql';
\i /tmp/alter_columns.sql
Be wary that changing an underlying column type in Postgres results in the entire table being rebuilt. This may require extended downtime, or a more protracted migration using logical replication to another cluster where the types have already been converted.
We should also convert any columns that reference these as foreign keys, since the types should match. The query that does this is rather daunting however, so if requested, we’ll share it in the comments.
Seeding the World
Let’s assume Dubai is the origin node. This is currently how we’d initialize a cluster using the upcoming BDR 3 syntax:
CREATE EXTENSION pglogical;
CREATE EXTENSION bdr;
SELECT bdr.create_node(
node_name := 'dubai',
local_dsn := 'dbname=storefront host=dubai.host'
);
SELECT bdr.create_node_group(
node_group_name := 'megacorp'
);
SELECT bdr.wait_for_join_completion();
With BDR, we “seed” a cluster from a single instance. In this case, the company started in Dubai.
Non Sequential
Now let’s fix those sequences. BDR 3 has a function that makes a metadata change so it treats a sequence as global automatically, using the 64-bit packing technique discussed earlier. We can bulk-convert all of them this way:
SELECT bdr.alter_sequence_set_kind(c.oid, 'timeshard')
FROM pg_class c
JOIN pg_namespace n ON (n.oid = c.relnamespace)
WHERE c.relkind = 'S'
AND n.nspname NOT IN (
'pg_catalog', 'information_schema', 'pg_toast',
'pglogical', 'bdr'
);
From this point on, values generated by nextval() for these sequences will be essentially arbitrary numeric results with up to 19 digits. For platforms that already use something like UUIDs, this kind of conversion isn’t necessary. And be wary of applications that may malfunction when interacting with such large numbers; numeric overflow is nobody’s friend.
Johnny Appleseed
Tokyo has the fastest RTT, so obviously it was the next step as the company grew. Let’s create a node there now on an empty shell database:
CREATE EXTENSION pglogical;
CREATE EXTENSION bdr;
SELECT bdr.create_node(
node_name := 'tokyo',
local_dsn := 'dbname=storefront host=tokyo.host'
);
SELECT bdr.join_node_group(
join_target_dsn := 'dbname=storefront host=dubai.host'
);
SELECT bdr.wait_for_join_completion();
Looks similar to creating the seed node, right? The only difference is that we need to join an existing BDR cluster instead of starting a new one. And then we just keep repeating the process for Texas, Sydney, or wherever we want until we’re satisfied. Nodes everywhere, until latency is finally at an acceptable level.
Next Steps
Once the cluster exists:
- Point applications to local copies
- Create any necessary read replicas/caches
- Be smug (optional)
For every node we roll out, we can move the local application stack to use it instead of the initial copy in Dubai. That will make both the local users and the Dubai database much happier.
This also means each local BDR node can have any number of streaming replicas for read scaling or standby targets. This alone warrants another entire blog post, but we’ll save that for another time.
And of course if you’re so inclined, you can be happy for drastically improving the company’s application infrastructure. Don’t worry, we won’t judge.
Finishing UP
The remaining caveats aren’t too onerous.
Since BDR uses replication slots, if a node is unreachable, Postgres will begin to retain WAL files for consumption when it returns. To plan for this, we can just take the amount of WAL files that elapse over a certain time period. Each one is 16MB, which tells us how much space to set aside. If a node goes over this limit, we remove it.
Conflicts can be logged to a table, and we recommend enabling that functionality. Then a monitoring system should always watch the contents of that table on each individual node. Conflicts resolve locally, so if they happen, only the node that experienced the conflict will have rows there. Keep an eye on this to make sure BDR’s resolution was the right one.
A transaction on a local BDR node gets committed locally before it enters the Postgres logical replication stream. This asynchronous nature is a strength of why BDR works so well locally. It’s also the reason conflicts are possible. Keep this in mind and it will always be easier to troubleshoot conflicts.
In the end, we’re left with something that contributes to a global cumulative data resource, with the same responsiveness of local access. All thanks to harnessing some of the deeper capabilities of logical replication.
As long as we understand the inherent design limitations of multi-master architectures, we can safely deploy our application stack and dedicated databases anywhere in the world.
For more information on use cases, deployment strategies, and other concepts related to muli-master and BDR concepts, we have a Postgres-BDR whitepaper that goes into more depth about these topics.
This is a great introduction to BDR! Do you anticipate that you will release BDR3 as Open Source, or will this product remain proprietary to 2ndQ?
The official word on this is:
“BDR3 is a proprietary extension to open source PostgreSQL. We will continue to contribute features from BDR to open source PostgreSQL at the pace the community allows. Because of the pace of development of BDR, however, we expect the BDR extension to continue to be more feature rich than what is available as open source.”