
Performance limits of logical replication solutions
In the previous blog post, I briefly explained how we got the performance numbers published in the pglogical announcement. In this blog post I’d like to discuss the performance limits of logical replication solutions in general, and also how they apply to pglogical.
physical replication
Firstly, let’s see how physical replication (built into PostgreSQL since version 9.0) works. A somewhat simplified figure of the with two just two nodes looks like this:
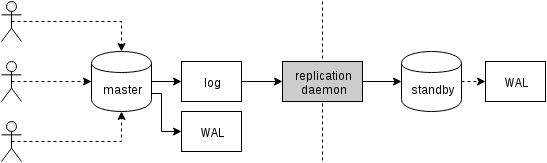
Clients execute queries on the master node, the changes are written to a transaction log (WAL) and copied over network to WAL on the standby node. The recovery on the standby process on the standby then reads the changes from WAL and applies them to the data files just like during recovery. If the standby is in “hot_standby” mode, clients may issue read-only queries on the node while this is happening.
This is very efficient because there’s very little additional processing – changes are transferred and written to the standby as an opaque binary blob. Of course, the recovery is not free (both in terms of CPU and I/O), but it’s difficult to get more efficient than this.
The obvious potential bottlenecks with physical replication are the network bandwidth (transferring the WAL from master to standby) and also the I/O on the standby, which may be saturated by the recovery process which often issues a plenty of random I/O requests (in some cases more than the master, but let’s not get into that).
logical replication
Logical replication is a bit more complicated, as it does not deal with opaque binary WAL stream, but a stream of “logical” changes (imagine INSERT, UPDATE or DELETE statements, although that’s not perfectly correct as we’re dealing with structured representation of the data). Having the logical changes allows doing interesting stuff like conflict resolution, replicating only selected tables, to a different schema or between different versions (or even different databases).
There are different ways to get the changes – the traditional approach is by using triggers recording the changes into a table, and let a custom process continuously read those changes and apply them on the standby by running SQL queries. And all this is driven by an external daemon process (or possibly multiple processes, running on both nodes), as illustrated on the next figure
That is what slony or londiste do, and while it worked quite well, it means a lot of overhead – for example it requires capturing the data changes and writing the data multiple times (to the original table and to a “log” table, and also to WAL for both those tables). We’ll discuss other sources of overhead later. While pglogical needs to achieve the same goals, it achieves them differently, thanks to several features added to recent PostgreSQL versions (thus not available back when the other tools were implemented):
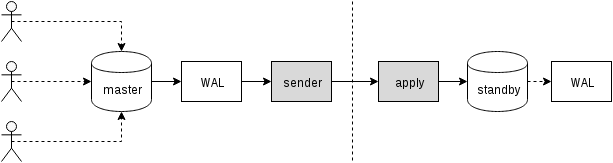
That is, instead of maintaining a separate log of changes, pglogical relies on WAL – this is possible thanks to a logical decoding available in PostgreSQL 9.4, which allows extracting logical changes from WAL log. Thanks to this pglogical does not need any expensive triggers and can usually avoid writing the data twice on the master (except for large transactions that may spill to disk).
After decoding each transaction, it gets transferred to the standby and the apply process applies its changes to the standby database. pglogical does not apply the changes by running regular SQL queries, but at a lower level, bypassing the overhead associated with parsing and planning SQL queries. This gives pglogical a significant advantage over the existing solutions that all go through the SQL layer (thus paying the parsing and planning).
potential bottlenecks
Clearly, logical replication is susceptible to the same bottlenecks as physical replication, i.e. it’s possible to saturate network when transferring the changes, and I/O on the standby when applying them on the standby. There is also a fair amount of overhead due to additional steps not present in a physical replication.
We need to somehow collect the logical changes, while physical replication simply forwards the WAL as stream of bytes. As already mentioned, existing solutions usually rely on triggers writing the changes to a “log” table. pglogical instead relies on the write-ahead log (WAL) and logical decoding to achieve the same thing, which is cheaper than triggers and also does not need to write the data twice in most cases (with the added bonus that we automatically apply the changes in commit order).
That is not to say there are no opportunities for additional improvement – for example the decoding currently only happens once the transaction gets committed, so with large transactions this may increase replication lag. Physical replication simply streams the WAL changes to the other node and thus does not have this limitation. Large transactions may also spill to disk, causing duplicate writes, because the upstream has to store them until they commit and they can be sent to the downstream.
Future work is planned to allow pglogical to begin streaming large transactions while they’re still in progress on the upstream, reducing the latency between upstream commit and downstream commit and reducing upstream write amplification.
After the changes are transferred to the standby, the apply process needs to actually apply them somehow. As mentioned in the previous section, the existing solutions did that by constructing and executing SQL commands, while pglogical bypasses the SQL layer and the associated overhead entirely.
Still, that doesn’t make the apply entirely free as it still needs to perform things like primary key lookups, update indexes, execute triggers and perform various other checks. But it’s significantly cheaper than the SQL-based approach. In a sense it works a lot like COPY and is especially fast on simple tables with no triggers, foreign keys, etc.
In all of the logical replication solutions each of those steps (decoding and apply) happen in a single process, so there’s quite a limited amount of CPU time. This is probably the most pressing bottleneck in all the existing solutions, because you may have quite a beefy machine with tens or even hundreds of clients running queries in parallel, but all of that needs to go through a single process decoding those changes (on the master) and one process applying those changes (on the standby).
The "single process" limitation may be somewhat relaxed by using separate databases, as each database is handled by a separate process. When it comes to a single database, future work is planned to parallelize apply via a pool of background workers to alleviate this bottleneck.
Great article, thanks!!
cool work, thx for this detailed explanation!
Pgq (londiste) — N upstream queues –> M subscribers. No “single process”.
Yes, that’s the easy solution to this and pglogical supports this “manual” parallelism as well, but that way you can’t guarantee that the changes are replicated in commit order anymore.
not exactly what I mean.
I am talking about upstream side. about cpu/io bottleneck on WAL parsing phase.
And second point about “commit order”:
* in parallel consumption mode — of course no one can guarantee order of commits for WHOLE dataset in cluster;
* BUT for one ROW (“one object”) we DO have the same order as on master. It based on producer’s lock contention on each row.
Hello,
In a bottleneck section is a comment:
“Future work is planned to allow pglogical to begin streaming large transactions while they’re still in progress on the upstream, reducing the latency between upstream commit and downstream commit and reducing upstream write amplification”
May I ask when this is planned to be implemented?
Thanks