Rendimiento OLTP desde PostgreSQL 8.3
Hace un par de años (en el pgconf.eu 2014 en Madrid) presenté una charla titulada «Arqueología del rendimiento«. Mostraba el cambio en el rendimiento alcanzado con las recientes versiones de PostgreSQL. Di esa charla porque considero que una visión a largo plazo es algo interesante y puede ofrecernos ideas muy valiosas. Para los que, como yo, trabajamos con el código PostgreSQL, representa una guía muy útil para el desarrollo futuro, y puede ayudar a los usuarios de PostgreSQL a evaluar las actualizaciones.
Así que he decidido repetir este ejercicio y escribir un par de posts en este blog para analizar el rendimiento de varias versiones de PostgreSQL. En la charla de 2014 empecé con PostgreSQL 7.4, que en aquel momento tenía unos 10 años de vida, puesto que fue lanzado en el año 2003. Esta vez empezaré con PostgreSQL 8.3, que ya tiene unos 12 años.
Por qué no empezar de nuevo con PostgreSQL 7.4? Existen tres razones principales por las que quiero empezar con PostgreSQL 8.3. En primer lugar, por pereza en general. Cuanto más anticuada sea una versión, más difícil será compilar usando las actuales versiones de los compiladores, etc. En segundo lugar, realizar pruebas de rendimiento adecuadas requiere mucho tiempo, especialmente cuando se trabaja con grandes cantidades de datos, por lo que añadir una sola versión principal puede suponer fácilmente un par de días de tiempo de máquina. Simplemente no parecía valer la pena. Y por último, la versión 8.3 introdujo una serie de cambios importantes – mejoras del proceso de autovacuum (habilitado por defecto, procesos ayudantes concurrentes, …), búsqueda de texto completo integrada, puntos de control extendidos, etc. Así que, en mi opinión, tiene mucho sentido empezar con PostgreSQL 8.3. Y puesto que fue lanzado hace unos 12 años, esta comparación abarca un período de tiempo superior a la anterior.
He decidido realizar una prueba de rendimiento con tres tipos básicos de carga de trabajo: OLTP, analítica y búsqueda de texto completo. Creo que la OLTP y la analítica son opciones bastante obvias, ya que la mayoría de las aplicaciones son una combinación de estos dos tipos básicos. La búsqueda de texto completo me permite demostrar las mejoras en los tipos especiales de índices, utilizados también para indexar tipos de datos populares como JSONB, tipos utilizados por PostGIS, etc.
¿Por qué realizar una prueba de rendimiento?
¿Vale la pena el esfuerzo? Después de todo, durante la fase de desarrollo realizamos constantemente pruebas de rendimiento para comprobar la utilidad de alguna revisión o para evitar que se produzcan regresiones, ¿verdad? El problema es que normalmente se trata sólo de pruebas "parciales", en las que se comparan dos commits específicos con una selección muy limitada de cargas de trabajo que consideramos relevantes. Y eso tiene sentido. Simplemente no es posible realizar una serie completa de cargas de trabajo para cada commit.
De vez en cuando (por lo general poco después del lanzamiento de una nueva versión principal de PostgreSQL) los usuarios realizan pruebas para comparar la nueva versión con la anterior. Eso es bueno y, de hecho, les recomiendo que hagan este tipo de pruebas, (de tipo estándar o específicas para la aplicación que realicen). Pero es difícil combinar estos resultados con una visión a largo plazo, debido a que estas pruebas se realizan empleando distintos tipos de configuración, de equipos (por lo general uno más reciente para la versión más actual), y otros elementos. Así que es difícil emitir juicios bien definidos sobre los cambios generales.
Lo mismo ocurre con el rendimiento de la aplicación, que, por supuesto, constituye el "criterio de referencia definitivo". Sin embargo, es posible que los usuarios no realicen la actualización a todas las versiones principales (en ocasiones pueden saltarse un par de versiones, por ejemplo, de la 9.5 a la 12). Y cuando deciden actualizar, a menudo lo hacen en combinación con actualizaciones de hardware, o de otro tipo. Cabe mencionar también que con el paso del tiempo las aplicaciones evolucionan (nuevas características, mayor complejidad), la cantidad de datos y el número de usuarios simultáneos aumentan, etc.
Eso es precisamente lo que esta serie de blogs quiere presentar: tendencias a largo plazo en el rendimiento de PostgreSQL relativas a algunas cargas de trabajo básicas. Esto dará a nosotros, los desarrolladores, la agradable sensación de haber realizado un buen trabajo a lo largo de los años. Mostrará también a los usuarios que, aunque PostgreSQL es un producto bien desarrollado, sigue ofreciendo mejoras significativas en cada nueva versión principal.
Mi intención no es utilizar estos parámetros para comparar distintos sistemas de bases de datos, ni presentar resultados que se ajusten a alguna clasificación oficial (como la del TPC-H). Mi objetivo es simplemente educarme como desarrollador de PostgreSQL, tal vez identificar e investigar algunos problemas, y compartir con otros mis conclusiones.
¿Comparación ecuánime?
Pienso que ninguna comparación entre las versiones publicadas en los últimos 12 años puede ser totalmente ecuánime. La razón es que cada software, para un sistema de base de datos, se desarrolla en un contexto específico, como por ejemplo el hardware. Piensen en las máquinas utilizadas hace 12 años: ¿cuántos núcleos tenían, cuánta memoria RAM? ¿Qué tipo de almacenamiento utilizaban?
Un típico servidor de rango medio en el año 2008 contaba quizás con 8-12 núcleos, 16 GB de RAM y un RAID con un par de unidades SAS. En la actualidad, un típico servidor de rango medio puede contar con un par de docenas de núcleos, cientos de GB de RAM y almacenamiento SSD.
El desarrollo de software está organizado por prioridades: siempre habrá más tareas que tiempo disponible. Por eso, es necesario seleccionar las tareas que ofrezcan la mejor relación costo-beneficio para los usuarios (especialmente los que financian directa o indirectamente el proyecto). Además, en el año 2008 algunas optimizaciones probablemente aún no eran relevantes. Por ejemplo, la mayoría de las máquinas no contaban con cantidades extremas de RAM, por lo que la optimización para grandes buffers compartidos aún no valía la pena. Por otro lado, muchos de los cuellos de botella de la CPU fueron eclipsados por el I/O, ya que la mayoría de las máquinas empleaban unidades de disco duro para el almacenamiento de datos.
Nota: Por supuesto, ya en esa época había clientes que usaban máquinas de mayor desempeño. Algunos usaban la versión comunitaria de Postgres con varios ajustes, otros decidieron utilizar una de las distintas variantes (forks) de Postgres con capacidades adicionales (por ejemplo, paralelismo masivo, consultas distribuidas, uso de FPGA, etc.). Por supuesto, esto también contribuyó al desarrollo de la comunidad.
A lo largo de los años, a medida que las máquinas de mayor desempeño se hicieron más comunes, más usuarios pudieron permitirse equipos con grandes cantidades de memoria RAM y un alto número de núcleos, lo cual incrementó la relación costo-beneficio. Los cuellos de botella fueron analizados y solucionados, permitiendo un mejor rendimiento de las nuevas versiones.
Esto significa que una prueba de rendimiento como esta siempre es un poco parcial. Dependiendo de la configuración (hardware, software), favorecerá a la versión más antigua o a la más reciente. De todas formas, he intentado elegir los parámetros del hardware y de la configuración para que el resultado no sea tan negativo para las versiones más antiguas.
El punto que estoy tratando de explicar es que lo anterior no significa que las versiones más antiguas de PostgreSQL fueran pésimas. Así es como funciona el desarrollo de software. Se abordan los cuellos de botella que los usuarios pueden encontrar con los sistemas actuales, no los que podrían encontrar de aquí a 10 años.
Hardware
Prefiero realizar pruebas de rendimiento basadas en el hardware físico al cual tengo acceso directo. Entre otras cosas, esto me permite disponer de todos los detalles y controlarlos. Así que he utilizado la máquina en nuestra oficina. Aunque no es nada sofisticado, considero sea lo suficientemente adecuada para este propósito.
- 2x E5-2620 v4 (16 núcleos, 32 hilos)
- 64GB RAM
- Intel Optane 900P 280GB NVMe SSD (data)
- 3 x 7.2k SATA RAID0 (tablespace temporal)
- kernel 5.6.15, ext4
- gcc 9.2.0, clang 9.0.1
pgbench
Para la prueba de rendimiento de todas las versiones he utilizado la última edición del conocido pgbench (incluida en PostgreSQL 13). Esto descarta posibles distorsiones debidas a las optimizaciones aportadas a pgbench a lo largo del tiempo, permitiendo que los resultados sean más comparables. La prueba de rendimiento evalúa diferentes situaciones, variando una serie de parámetros, como los siguientes:tamaño
- pequeño – los datos caben en los buffers de memoria compartidos, presentando problemas de bloqueo, etc.
- mediano – los datos exceden el tamaño de los buffers de memoria compartidos pero caben en la memoria RAM, normalmente están vinculados a la CPU (o posiblemente al I/O para las cargas de trabajo de lectura y escritura)
- grande – los datos exceden el tamaño de la RAM, principalmente vinculados al I/O
modos
- sólo lectura – pgbench -S
- lectura-escritura – pgbench -N
cantidad de clientes
- 1, 4, 8, 16, 32, 64, 128, 256
- el número de procesos de pgbench (-j) se ajusta en consecuencia
Resultados
OK, veamos los resultados. Presentaré primero los resultados del almacenamiento NVMe, luego mostraré algunos resultados interesantes usando el almacenamiento SATA RAID.NVMe SSD / sólo lectura
Para el conjunto de datos de tamaño pequeño (que cabe completamente en los buffers de memoria compartidos), los resultados de sólo lectura aparecen así: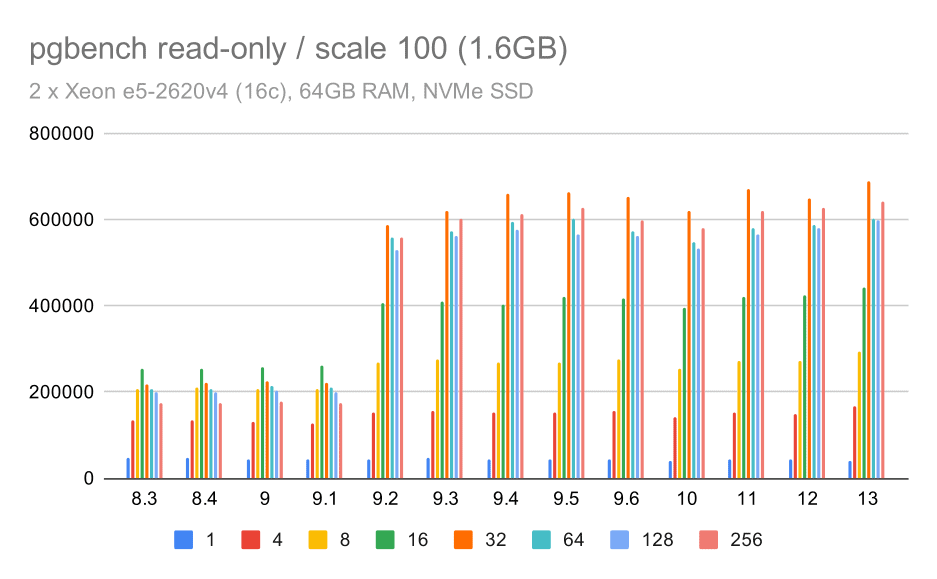
pgbench results / read-only on small data set (scale 100, i.e. 1.6GB)
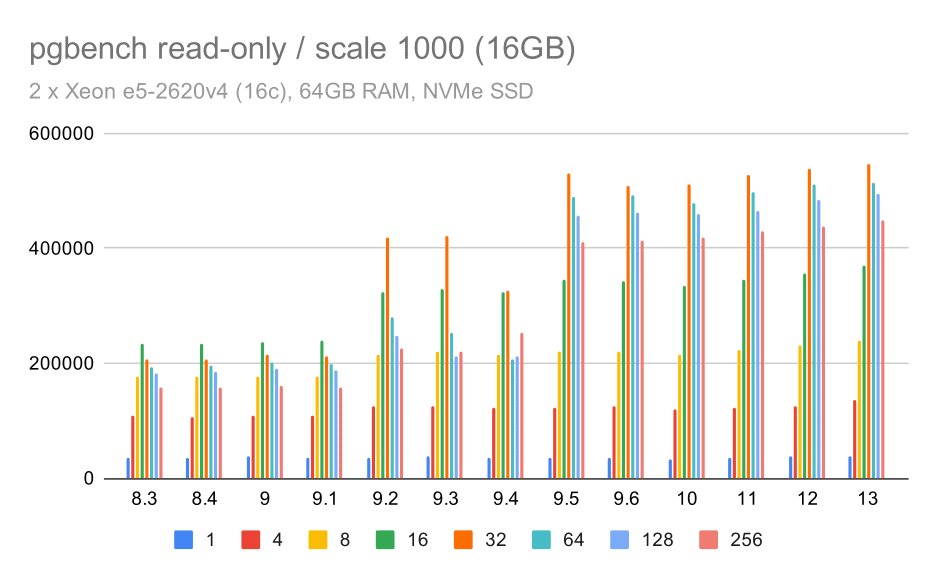
pgbench results / read-only on medium data set (scale 1000, i.e. 16GB)
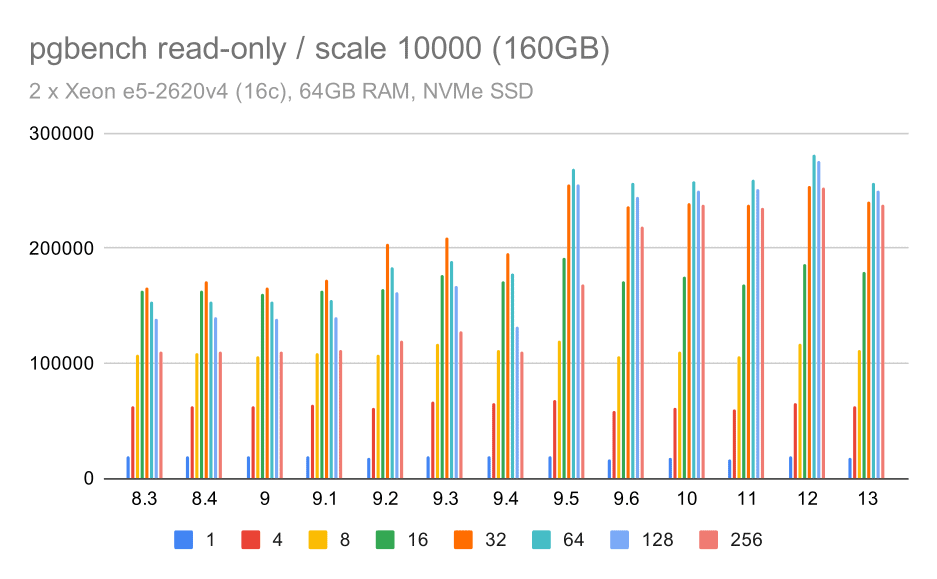
pgbench results / read-only on large data set (scale 10000, i.e. 160GB)
NVMe SSD / lectura-escritura
Los resultados obtenidos en la modalidad de lectura-escritura también muestran algunas mejoras, aunque no tan pronunciadas. En el conjunto de datos de tamaño pequeño, los resultados se observan así:
pgbench results / read-write on small data set (scale 100, i.e. 1.6GB)

pgbench results / read-write on medium data set (scale 1000, i.e. 16GB)

pgbench results / read-write on large data set (scale 10000, i.e. 160GB)
SATA RAID / sólo lectura
Para el almacenamiento SATA RAID, los resultados de sólo lectura no son tan favorables. Podemos ignorar los conjuntos de datos de tamaño pequeño y mediano, para los cuales el sistema de almacenamiento es irrelevante. Para el conjunto de datos de gran tamaño, el rendimiento es bastante elevado, aunque parece disminuir con el tiempo, especialmente desde la versión 9.6 de PostgreSQL. Desconozco la razón del problema (nada en las notas de la versión 9.6 se destaca claramente como elemento sospechoso), pero parece existir algún tipo de regresión.
pgbench results on SATA RAID / read-only on large data set (scale 10000, i.e. 160GB)
SATA RAID / lectura-escritura
Sin embargo, el comportamiento en la modalidad de lectura-escritura parece mucho más favorable. En el conjunto de datos de tamaño pequeño, el rendimiento incrementa de unas 600 tps a más de 6000 tps. Me atrevería a afirmar que esto se debe a las mejoras en el group commit en las versiones 9.1 y 9.2.
pgbench results on SATA RAID / read-write on small data set (scale 100, i.e. 1.6GB)

pgbench results on SATA RAID / read-write on medium data set (scale 1000, i.e. 16GB)

pgbench results on SATA RAID / read-write on large data set (scale 10000, i.e. 160GB)
Conclusión y perspectiva futura
En resumen, para la configuración con almacenamiento NVMe los resultados parecen ser muy positivos. En la carga de trabajo de sólo lectura se observa un incremento moderado de la velocidad de ejecución en la versión 9.2 y un incremento significativo en la 9.5, gracias a las optimizaciones de la escalabilidad. En cambio, a lo largo del tiempo, en la carga de trabajo de lectura-escritura aplicada a múltiples versiones principales e intermedias, el rendimiento ha aumentado aproximadamente de dos veces. Sin embargo, las conclusiones de la prueba con la configuración SATA RAID son algo contradictorias. En el caso de la carga de trabajo de sólo lectura existe mucha variabilidad/fluctuación, y una posible regresión en la versión 9.6. Para la carga de trabajo de lectura-escritura, se registra un considerable aumento de la velocidad de ejecución en la versión 9.1, con un incremento repentino del rendimiento que pasa de 100 tps a 600 tps, aproximadamente.¿Qué mejoras se introducirán en las futuras versiones de PostgreSQL? La verdad es que no tengo una idea muy clara de cuál será la próxima novedad importante, pero estoy seguro de que otros desarrolladores de PostgreSQL tendrán ideas geniales que harán las cosas más eficientes o permitirán aprovechar los recursos hardware disponibles. La revisión que mejora la escalabilidad en un sistema con muchas conexiones, o la que añade soporte para buffers WAL no volátiles son ejemplos de estas mejoras. Podríamos ser testigos de algunas mejoras radicales en el almacenamiento PostgreSQL (formato en disco más eficiente, uso de I/O directo, etc.), indexación, etc.


Dejar un comentario
¿Quieres unirte a la conversación?Siéntete libre de contribuir!