Rendimiento TPC-H desde PostgreSQL 8.3
En la primera parte de esta serie de blogs, he presentado los resultados de un par de pruebas comparativas que ilustran cómo ha cambiado el rendimiento OLTP de PostgreSQL desde la versión 8.3, publicada en 2008. En esta parte haré lo mismo, aunque me enfocaré en las consultas analíticas y de inteligencia empresarial que procesan grandes cantidades de datos.
Entre el gran número de pruebas de rendimiento profesionales para evaluar este tipo de carga de trabajo, probablemente la más utilizada es la TPC-H. Así que esta es la que usaré en este post. Existe también la TPC-DS (otra prueba de rendimiento TPC que puede ser considerada como una evolución o un reemplazo de la TPC-H) utilizada para analizar los sistemas de soporte a la decisión. He decidido utilizar la TPC-H por un par de razones.
En primer lugar, la TPC-DS es mucho más compleja, tanto en términos de esquema (más tablas) como de número de consultas (22 contra 99). Ajustarla de forma adecuada, particularmente cuando se trata de múltiples versiones de PostgreSQL, resultaría mucho más complicado. En segundo lugar, algunas de las consultas TPC-DS utilizan características (por ejemplo, conjuntos de agrupación) que no son soportadas por las versiones más antiguas de PostgreSQL. En consecuencia, esas consultas resultan irrelevantes para algunas versiones. Y finalmente, diría que la gente está mucho más familiarizada con la TPC-H que con la TPC-DS.
El objetivo no es hacer comparaciones con otras bases de datos, sino proporcionar una caracterización razonable y a largo plazo de la evolución del rendimiento de PostgreSQL desde su versión 8.3.
Nota: Para un análisis más interesante de la prueba de rendimiento TPC-H, recomiendo vivamente el documento “TPC-H Analyzed: Hidden Messages and Lessons Learned from an Influential Benchmark” de Boncz, Neumann y Erling.
El hardware
La mayoría de los resultados que aparecen en este post han sido obtenidos utilizando la "caja más grande" entre las que tenemos en nuestra oficina. Estos son sus parámetros:
- 2x E5-2620 v4 (16 núcleos, 32 hilos)
- 64GB RAM
- Intel Optane 900P 280GB NVMe SSD (data)
- 3 x 7.2k SATA RAID0 (tablespace temporal)
- kernel 5.6.15, ext4 filesystem
Estoy seguro de que se pueden conseguir máquinas de mayor desempeño, aunque creo que esta es lo suficientemente adecuada para darnos datos relevantes. Existen dos variantes de configuración: una con el paralelismo desactivado, y otra con el paralelismo activado. La mayoría de los valores de los parámetros son los mismos en ambos casos, ajustados a los recursos hardware disponibles (CPU, RAM, almacenamiento). Al final de este artículo encontrará información más detallada sobre la configuración.
La prueba de rendimiento
Quiero dejar muy claro que mi objetivo no es realizar una prueba de rendimiento TPC-H válida, que pueda satisfacer todos los criterios TPC requeridos. Tampoco quiero perseguir alguna medida abstracta de rendimiento (por dólar o algo parecido) sino evaluar cómo el rendimiento de las diferentes consultas analíticas ha cambiado con el paso del tiempo.
Así que he decidido usar sólo un subconjunto TPC-H. Básicamente, sólo cargaré los datos y ejecutaré las 22 consultas utilizando los mismos parámetros para todas las versiones. Los datos no se actualizarán. Tras la carga inicial, el conjunto de datos permanecerá estático. He elegido una serie de factores de escala, 1, 10 y 75, para disponer de resultados relativos a datos que caben en los buffers compartidos (1), caben en la memoria (10) y exceden el tamaño de la memoria (75). Subiría a 100 para que fuera una "buena secuencia", la cual, en algunos casos, no entraría en los 280 GB de almacenamiento (debido a los índices, archivos temporales, etc.). Hay que tener en cuenta que el factor de escala 75 ni siquiera es considerado como un factor de escala TPC-H válido.
Pero, ¿tiene sentido realizar una prueba de rendimiento con conjuntos de datos de 1 o de 10GB? La tendencia general es enfocarse en bases de datos mucho más grandes, así que podría parecer algo absurdo tomarse la molestia de probarlas. Sin embargo, no creo que sea necesaria una prueba con una base de datos de gran tamaño, puesto que la gran mayoría de las bases de datos existentes, según mi experiencia, son bastante pequeñas. Incluso en el caso de que la base de datos sea de gran tamaño, la gente suele trabajar sólo con un pequeño subconjunto de la misma: datos recientes, pedidos pendientes, etc. Así que creo que tiene sentido hacer pruebas incluso con esos pequeños conjuntos de datos.
Cargas de datos
Primero, veamos cuánto tiempo es necesario para cargar los datos en la base de datos – sin y con paralelismo. Mostraré únicamente los resultados del conjunto de datos de 75 GB, porque en el caso de los tamaños menores el comportamiento general es muy similar.
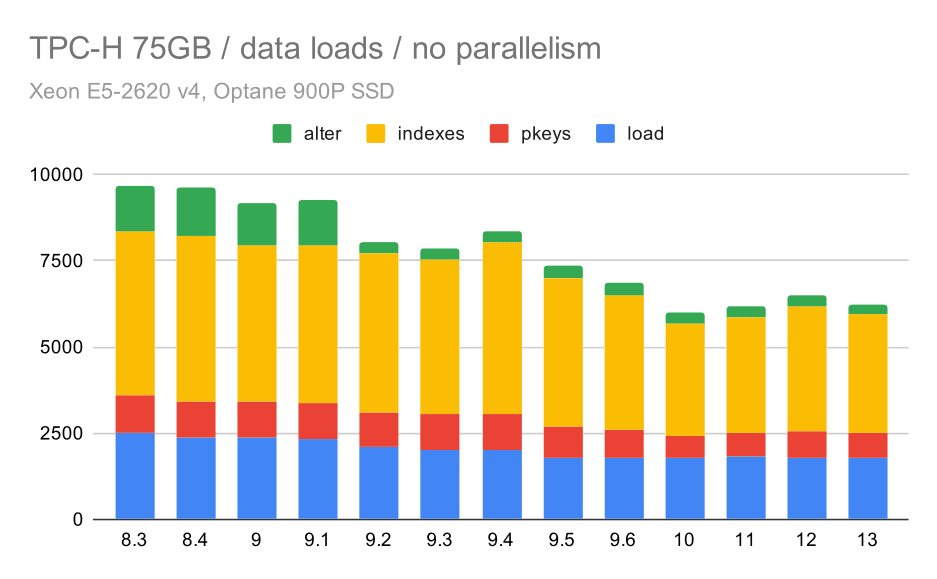
TPC-H data load duration – scale 75GB, no parallelism
Se puede observar claramente una tendencia constante al mejoramiento. Se ahorra alrededor del 30% del tiempo simplemente mejorando la eficiencia en los cuatro pasos: COPY, creación de claves e índices primarios, y (especialmente) estableciendo claves foráneas. La mejora de «alter» en la versión 9.2 es especialmente evidente.
| COPY | PKEYS | INDEXES | ALTER | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8.4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9.5 | 1982 | 1000 | 1903 | 1203 |
| 9.6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
Ahora, veamos cómo cambia el comportamiento activando el paralelismo. El siguiente gráfico compara los resultados obtenidos con el paralelismo activado (marcado con "(p)") con los resultados con el paralelismo desactivado.

TPC-H data load duration – scale 75GB, parallelism enabled.
Lamentablemente, parece que el efecto del paralelismo es muy limitado en esta prueba. Aunque ayuda un poco, las diferencias son mínimas. Así que la mejora general se mantiene en un 30%.
| COPY | PKEYS | INDEXES | ALTER | |
| 9.6 | 344 | 3902 | 1786 | 831 |
| 9.6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
Consultas
Echemos ahora un vistazo a las consultas. TPC-H cuenta con 22 plantillas de consultas. He generado un conjunto de consultas reales, que he ejecutado dos veces en todas las versiones: primero después de haber vaciado todas las cachés y reiniciado la instancia, y luego con la caché llena. En los gráficos se presentan los mejores entre los valores de las dos ejecuciones, que en la mayoría de los casos han sido obtenidos en la segunda ejecución.
Paralelismo desactivado
Con el paralelismo desactivado, los resultados en el conjunto de datos de menor tamaño son bastante claros. Los colores de las diferentes partes de cada barra representan las 22 consultas. Es difícil determinar qué parte corresponde exactamente a cada consulta. De todas formas, el gráfico permite identificar los casos en los que una consulta mejora o empeora entre las dos ejecuciones. Por ejemplo, en el primer gráfico es evidente que la consulta Q21 fue mucho más rápida entre las versiones 8.3 y 8.4.

TPC-H queries on small data set (1GB) – parallelism disabled
En el tamaño de 10 GB, los resultados son más difíciles de interpretar, puesto que en la versión 8.3 una de las consultas (Q21) tarda mucho tiempo en ejecutarse, llegando al punto de eclipsar todo el resto.

TPC-H queries on medium data set (10GB) – parallelism disabled
Veamos cómo quedaría el gráfico sin la consulta Q21:

TPC-H queries on medium data set (10GB) – parallelism disabled, without problematic Q2
Este gráfico es más fácil de entender. Se puede observar claramente que la mayoría de las consultas (hasta la Q17) fueron más rápidas, aunque dos de ellas (Q18 y Q20) luego resultaron más lentas. Observaremos un problema similar en el conjunto de datos de mayor tamaño, así que luego explicaré la posible causa.

TPC-H queries on large data set (75GB) – parallelism disabled
En el caso de la consulta Q2 en la versión 9.3, se observa nuevamente un incremento repentino del tiempo de ejecución. Excluyendo dicha consulta el gráfico se presenta así:

TPC-H queries on large data set (75GB) – parallelism disabled, without problematic Q2
Se trata de una importante mejora general, que reduce el tiempo de ejecución total de 2,7 a sólo 1,2 horas, simplemente haciendo más inteligente el planificador y optimizador y más eficiente el ejecutor (recuerde que el paralelismo fue desactivado).
Entonces, ¿cuál podría ser el problema de lentitud con la consulta Q2 en la versión 9.3? La explicación sencilla es que cada vez que se hace más inteligente el planificador y optimizador, ya sea creando nuevos tipos de rutas o planes, o subordinándolo a algunas estadísticas, existe la posibilidad de incurrir en nuevos errores si dichas estadísticas o estimaciones resultaran incorrectas. En la consulta Q2, la cláusula WHERE hace referencia a una subconsulta agregada. Una versión simplificada de la consulta podría presentarse así:
select 1 from partsupp where ps_supplycost = ( select min(ps_supplycost) from partsupp, supplier, nation, region where p_partkey = ps_partkey and s_suppkey = ps_suppkey and s_nationkey = n_nationkey and n_regionkey = r_regionkey and r_name = 'AMERICA' );
El problema es que no conocemos el valor promedio al momento de la planificación. Esto impide obtener estimaciones válidas para la condición WHERE. La consulta Q2 contiene joins adicionales, cuya planificación depende fundamentalmente de una correcta estimación de las relaciones unidas. En las versiones anteriores el optimizador parece haber funcionado correctamente. Sin embargo, aunque desde la versión 9.3 lo hemos hecho más inteligente, su mala estimación le impide tomar decisiones correctas. En otras palabras, los buenos planes de las versiones anteriores sólo fueron mera coincidencia, debido a las limitaciones del planificador.
Aunque no las he investigado en detalle, me atrevería a decir que las regresiones de las consultas Q18 y Q20, en el conjunto de datos de menor tamaño, se deben a alguna causa similar.
En mi opinión, algunos de esos problemas de optimización podrían solucionarse ajustando los parámetros de costo (por ejemplo, random_page_cost etc.), aunque por falta de tiempo no lo he intentado. Sin embargo, esto demuestra que las actualizaciones no mejoran todas las consultas de manera automática: a veces una actualización puede desencadenar una regresión, por lo que siempre resulta conveniente probar la aplicación de manera adecuada.
Paralelismo activado
Consideremos ahora en qué medida el paralelismo de las consultas puede cambiar los resultados. Una vez más, analizaremos únicamente los resultados desde la versión 9.6 en adelante, etiquetándolos con una "(p)" cuando la consulta paralela esté activada.

TPC-H queries on small data set (1GB) – parallelism enabled
Obviamente, el paralelismo es de gran ayuda, ya que el tiempo de ejecución se reduce en un 30% incluso con el conjunto de datos de menor tamaño. En el conjunto de datos de tamaño medio, no existe mucha diferencia entre las ejecuciones regulares y paralelas:

TPC-H queries on medium data set (10GB) – parallelism enabled
Esto confirma el razonamiento anterior: aunque habilitar el paralelismo permite añadir planes de consulta adicionales, es evidente que estimaciones o cálculos de costos erróneos resultarán en una mala elección de los planes.
Finalmente, en el conjunto de datos de gran tamaño los resultados son los siguientes:

TPC-H queries on large data set (75GB) – parallelism enabled
Aquí el paralelismo representa una ventaja, puesto que el optimizador logra crear un plan paralelo más económico para la consulta Q2, anulando la mala elección de plan introducida en la versión 9.3. Y para completar, estos son los resultados sin la consulta Q2:

TPC-H queries on large data set (75GB) – parallelism enabled, without problematic Q2
Incluso en este caso se pueden observar algunas malas elecciones en cuanto a los planes paralelos. Por ejemplo, el plan paralelo para la consulta Q9 es peor hasta la versión 11. De allí en adelante, se hace más rápido, probablemente gracias a los 11 nodos ejecutores paralelos adicionales. Por otro lado, algunas consultas paralelas (Q18, Q20) se vuelven más lentas en la versión 11, así que no todo es color de rosa.
Conclusión y perspectiva futura
Creo que estos resultados evidencian claramente las optimizaciones implementadas desde PostgreSQL 8.3. Las pruebas con el paralelismo desactivado ilustran las mejoras en la eficiencia (es decir, realizar más con la misma cantidad de recursos). Las cargas de datos se aceleraron en un 30% y las consultas se hicieron dos veces más rápidas. Es cierto que se han presentado algunos problemas relacionados con planes de consulta ineficientes, pero eso es un riesgo intrínseco cuando queremos un planificador de consultas más inteligente. Se sigue trabajando para que los resultados sean más fiables. Además, estoy seguro de que la mayoría de estos problemas se pueden mitigar ajustando un poco la configuración.
Los resultados con el paralelismo activado muestran que podemos utilizar los recursos adicionales de manera más eficiente (en particular los núcleos de la CPU). No parece haber un gran beneficio para las cargas de datos, al menos no en esta prueba de rendimiento. Sin embargo, el impacto en la ejecución de las consultas es significativo, puesto que la velocidad aproximada es dos veces mayor (aunque, por supuesto, las diferentes consultas se ven afectadas de forma diferente).
Existen muchas oportunidades de mejorar todo esto en futuras versiones de PostgreSQL. Por ejemplo, se han creado una serie de revisiones que, implementando el paralelismo para la función COPY, aceleran la carga de datos. Existen otras que mejoran la ejecución de las consultas analíticas: desde pequeñas optimizaciones localizadas hasta grandes proyectos como el almacenamiento y la ejecución de columnas, la aplicación de agregados, etc. Se puede lograr mucho usando también el particionamiento declarativo, una característica que básicamente he ignorado en esta prueba de rendimiento, simplemente porque habría aumentado demasiado el alcance de la misma prueba. Estoy seguro de que existen muchas otras oportunidades que ni siquiera puedo imaginarme. Pero hay gente más inteligente, en la comunidad PostgreSQL, que ya está trabajando en ellas.
Apéndice: Configuración de PostgreSQL
Paralelismo desactivado
shared_buffers = 4GB work_mem = 128MB vacuum_cost_limit = 1000 max_wal_size = 24GB checkpoint_timeout = 30min checkpoint_completion_target = 0.9 # logging log_checkpoints = on log_connections = on log_disconnections = on log_line_prefix = '%t %c:%l %x/%v ' log_lock_waits = on log_temp_files = 1024 # parallel query max_parallel_workers_per_gather = 0 max_parallel_maintenance_workers = 0 # optimizer default_statistics_target = 1000 random_page_cost = 60 effective_cache_size = 32GB
Paralelismo activado
shared_buffers = 4GB work_mem = 128MB vacuum_cost_limit = 1000 max_wal_size = 24GB checkpoint_timeout = 30min checkpoint_completion_target = 0.9 # logging log_checkpoints = on log_connections = on log_disconnections = on log_line_prefix = '%t %c:%l %x/%v ' log_lock_waits = on log_temp_files = 1024 # parallel query max_parallel_workers_per_gather = 16 max_parallel_maintenance_workers = 16 max_worker_processes = 32 max_parallel_workers = 32 # optimizer default_statistics_target = 1000 random_page_cost = 60 effective_cache_size = 32GB


Dejar un comentario
¿Quieres unirte a la conversación?Siéntete libre de contribuir!