
What’s New in PgBouncer 1.6
PgBouncer is a lightweight connection pooler for PostgreSQL.
PgBouncer 1.6 was announced on the 1st of August 2015. In this blog post we’ll talk about the major new improvements in PgBouncer.
Main new features of PgBouncer
Load user password hash from postgres database
PgBouncer now allows loading the user’s password from the database with two config parameters which are auth_user and auth_query.
Note: These config parameters are defined in the configuration file pgbouncer.ini.
- auth_user
If auth_user is set, any user not specified in auth_file will be queried from pg_shadow in the database using auth_user. Auth_user’s password will be taken from auth_file. This parameter can be set per-database too.Note: auth_file is the name of the file to load user names and passwords from.
- auth_query
This parameter allow us to write a SQL query to load user’s password from database. It runs under auth_user.See the default query below:SELECT usename, passwd FROM pg_shadow WHERE usename=$1
Pooling mode can be configured both per-database and per-user
With this feature, independent of the main pooling mode, clients can now connect to different databases with one of the 3 pooling modes described below. This is also applicable to users as well. For example, if the pooling mode is session pooling, a specific user can be configured to use transaction pooling. This gives us database-level and user-level flexibility to apply more appropriate pooling options.
PgBouncer provides 3 connection pooling modes:
- Session pooling
During the lifetime of a client connection, an existing server connection is assigned to the client and after the client disconnects, the assigned server connection is put back to the connection pool. - Transaction pooling
In this mode, a server connection is not assigned to a connected client immediately, but only during a transaction. As soon as the transaction is over, the connection is put back into the pool. - Statement pooling
This is similar to transaction pooling, but is more aggressive. A backend is assigned whenever any single-statement query is issued. When the statement is over, the connection is put back into pool.
Per-database and per-user connection limits: max_db_connections and max_user_connections
With this feature, now we can control also connection limits per database/user level with the two new parameters, which are max_db_connections and max_user_connections.
- max_db_connections
This parameter does not allow more than the specified connections per-database (regardless of pool – i.e. user).
The default value of this parameter is unlimited. - max_user_connections
This parameter does not allow more than the specified connections per-user (regardless of pool – i.e. user).
Add DISABLE/ENABLE commands to prevent new connections
With this feature PgBouncer have ENABLE/DISABLE db; commands to prevent new connections.
- DISABLE db;
This command rejects all new client connections on the given database. - ENABLE db;
This command allows new client connections after a previous DISABLE command.
Note: PgBouncer has several other process controlling commands. See the list below:
PAUSE [db]; PgBouncer tries to disconnect from all servers, first waiting for all queries to complete. The command will not return before all queries are finished. To be used at the time of database restart. If database name is given, only that database will be paused.
KILL db; Immediately drop all client and server connections on given database.
SUSPEND; All socket buffers are flushed and PgBouncer stops listening for data on them. The command will not return before all buffers are empty. To be used at the time of PgBouncer online reboot.
RESUME [db]; Resume work from previous PAUSE or SUSPEND command.
SHUTDOWN; The PgBouncer process will exit.
RELOAD; The PgBouncer process will reload its configuration file and update changeable settings.
New preferred DNS backend: c-ares
c-ares is the only DNS backend that supports all interesting features: /etc/hosts with refresh, SOA lookup, large replies (via TCP/EDNS+UDP), IPv6. It is the preferred backend now, and probably will be the only backend in future.
Note: See the following list which shows currently supported backends.
backend parallel EDNS0 /etc/hosts SOA lookup note c-ares yes yes yes yes ipv6+CNAME buggy in <=1.10 udns yes yes no yes ipv4-only evdns, libevent 2.x yes no yes no does not check /etc/hosts updates getaddrinfo_a, glibc 2.9+ yes yes yes no N/A on non-linux getaddrinfo, libc no yes yes no N/A on win32, requires pthreads evdns, libevent 1.x yes no no no buggy
Config files have ‘%include FILENAME’ directive to allow configuration to be split into several files
With this feature, PgBouncer has support for inclusion of config files within other config files.
In other words, PgBouncer config file can contain include directives, which specify another config file to read and process. This allows splitting a large configuration file to smaller and more manageable files. The include directives look like this:
%include filename
If the file name is not absolute path it is taken as relative to current working directory.
There are more features released in this version. You can visit the PgBouncer changelog page or check the list below for the other improvements:
- Show remote_pid in SHOW CLIENTS/SERVERS. Available for clients that connect over unix sockets and both tcp and unix socket server. In case of tcp-server, the pid is taken from cancel key.
- Add separate config param (dns_nxdomain_ttl) for controlling negative dns caching.
- Add the client host IP address and port to application_name. This is enabled by a config parameter application_name_add_host which defaults to ‘off’.
What is PgBouncer?
PgBouncer is a utility for managing client connections to the PostgreSQL database. In a nutshell, it maintains a connection pool to the PostgreSQL server and reuses those existing connections. While this can be useful for reducing the client connection overhead, it also enables limiting the maximum number of open connections to the database server. It can also be used for traffic shaping like redirecting connections to one or more databases to different database servers. In addition to these, PgBouncer can be used for managing security on user and even on database level.
See the diagram below which depicts PgBouncer architecture in a more visual way.
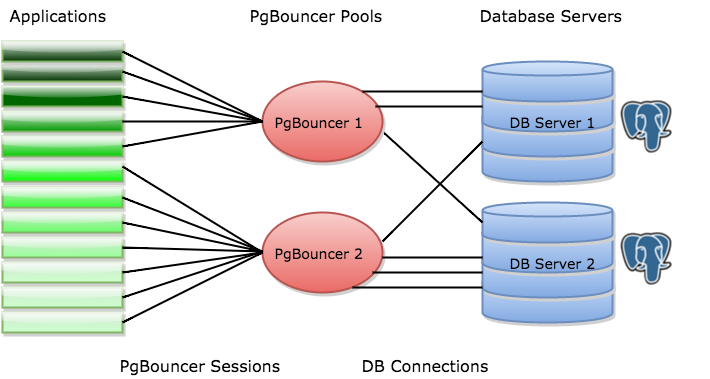
In this particular example, client applications are connected to separate PgBouncer instances where they would instead be connected to PostgreSQL database servers directly. Database servers “DB Server 1” and “DB Server 2” may be independent PostgreSQL instances or they may be a part of a cluster with different roles (e.g., master/replica or write-master/backup-master, etc.).
Each PgBouncer instance maintains a connection pool with a number of open connections to PostgreSQL servers. As it can be seen from the example, PgBouncers allows creating pools with connections to different databases and even connections to different database servers.
For more information
You can visit the main website of PgBouncer: http://pgbouncer.github.io/
They have a nice FAQ page: http://pgbouncer.github.io/faq.html
You can take a look to the Github repository of the project: http://github.com/pgbouncer/pgbouncer
should pgbouncer be located in app servers or db servers ?
I’m pasting the answer from FAQ page of PgBouncer:
“It depends. Installing on web server is good when short-connections are used, then the connection setup latency is minimised – TCP requires couple of packet roundtrips before connection is usable. Installing on database server is good when there are many different hosts (eg. web servers) connecting to it, then their connections can be optimised together.
It is also possible to install PgBouncer on both web server and database servers. Only negative aspect of that is that each PgBouncer hop adds small amount of latency to each query. So it’s probably best to simply test whether the payoff is worth the cost.”
New version looks great! Loading the password hash from the database means we no longer need to manually update the userlist.txt file.
We use the pgbouncer package from http://yum.postgresql.org/, but there seems to be no package for the new pgbouncer version. Any idea when the new version will be packaged?
RPM packaging depends on Devrim, hard to say when he gets to it.
Over 1000 concurrent users, pgbouncer works fine.
We have a problem about “prepare statement ” when using “Transaction pooling” mode.
With FAQ (https://pgbouncer.github.io/faq.html) we changed our configuration , but not succeed.
I think pgbouncer next version should fix it 🙂
Prepared statements are not supported in transaction pooling mode. It’s something that’s in TODO but it’s also quite a big feature so I don’t expect it very soon.
With this new version you can isolate your prepare statements using a different user and enabling session pool only to that user.