
Databases vs. encryption
Let’s assume you have some sensitive data, that you need to protect by encryption. It might be credit card numbers (the usual example), social security numbers, or pretty much anything you consider sensitive. It does not matter if the encryption is mandated by a standard like PCI DSS or if you just decided to encrypt the sensitive stuff. You need to do the encryption right and actually protecting the information in both cases. Unfortunately, full-disk-encrytion and pgcrypto are not a good fit for multiple reasons, and application-level encryption reduces the database to “dumb” storage. Let’s look at an alternative approach – offloading the encryption to a separate trusted component, implemented as a custom data type.
Note: A couple of weeks ago at pgconf.eu 2018, I presented a lightning talk introducing a PoC of an alternative approach to encrypting data in a database. I got repeatedly asked about various details since then, so let me just explain it in this blog post.
FDE and pgcrypto
In the PostgreSQL world, people will typically recommend two solutions to this problem – full-disk encryption and pgcrypto. Unfortunately, neither of them really works for this use case 🙁
Full-disk encryption (FDE) is great. It’s transparent to the database (and application), so there are no implementation changes needed. The overhead is very low, particularly when your CPU supports AES-NI etc. The problem is it only really protects against someone stealing the disk. It does not protect against OS-level attacks (rogue sysadmin, someone gaining remote access to the box or backups, …). Nor does it protect against database-level attacks (think SQL injection). And most importantly, it’s trivial to leak the plaintext data into server log, various monitoring systems etc. Not great.
pgcrypto addresses some of these issues as the encryption happens in the database. But it means the database has to know the keys, and those are likely part of SQL queries and so the issue with leaking data into server logs and monitoring systems is still there. Actually, it’s worse because this time we’re leaking the encryption keys, not just the plaintext data.
Application-level encryption
So neither full-disk encryption nor pgcrypto is a viable solution to the problem at hand. There inherent issue with both solutions is that the database sees plaintext data (on input), and so can leak them into various output channels. In case of pgcrypto the database actually sees the keys, and leaking those is even deadlier.
This is why many practical systems use application-level encryption – all the encryption/decryption happens in the application, and the database only sees encrypted data.
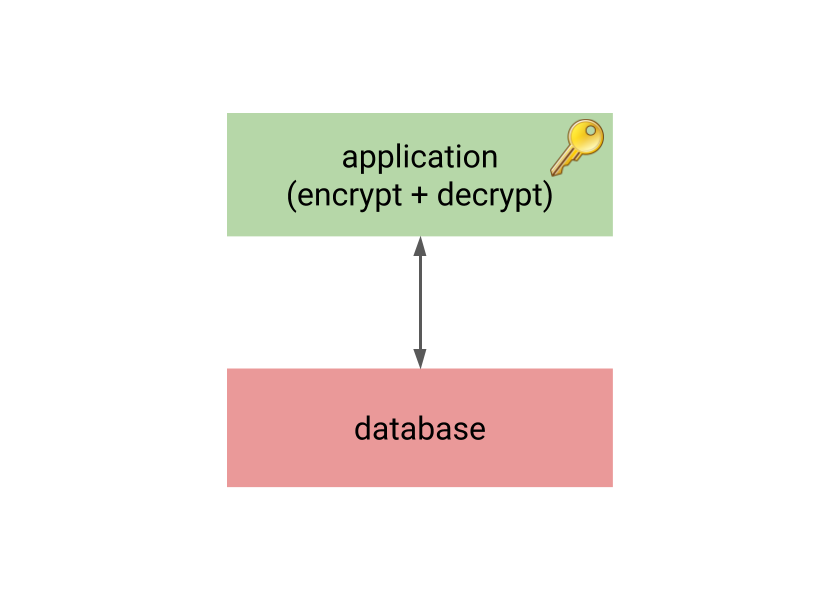
The unfortunate consequence is that the database acts as “dumb” storage, as it can’t do anything useful with the encrypted data. It can’t compare the plaintext values (it can’t even determine if two plaintext values are equal due to nonces), etc. That means it’s impossible to build indexes on the encrypted data, do aggregation, or anything that we expect from decent relational database.
There are workarounds for some of these issues. E.g. you may compute SHA-1 hash of the credit card number, build an index on it and use it for lookups, but this may weaken the encryption when the encrypted data have low entrophy (just like credit card numbers).
This means application-level encryption often results in a lot of the processing moves to the application, which is inefficient and error-prone. There must be a better solution …
Encryption off-loading
The good thing on application-level encryption is that the database does not know the plaintext or encryption keys, which makes the system safe. The problem is that the database has no way to perform interesting operations on the data, so a lot of the processing moves to the application level.
So let’s start with the application-level encryption, but let’s add another component to the system, performing the important operations on encrypted data on behalf of the database.
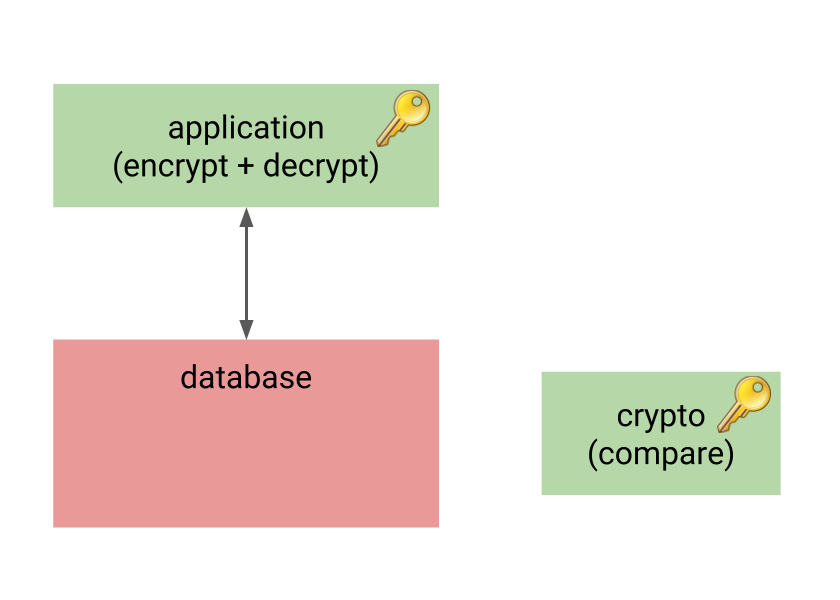
This component also knows the encryption keys, but it’s much smaller and simpler than the database. It’s only task is to receive encrypted data from the database, and perform some predefined operation(s) on it. For example, it might receive two encrypted values, decrypt and compare them, and return -1/0/1 just like regular comparator.
This way the database still does not know anything sensitive, yet it can meaningfully perform indexing, aggregation and similar tasks. And while there’s another component with the knowledge of encryption keys, it may be much simpler and smaller compared to the whole RDMBS, with much smaller attack surface.
The encryption component
But what is a “component” in this context? It might be as simple as a small service running on a different machine, communicating over TCP.

Or it might be a separate process running on the same host, providing better performance due to replacing TCP with some form of IPC communication.
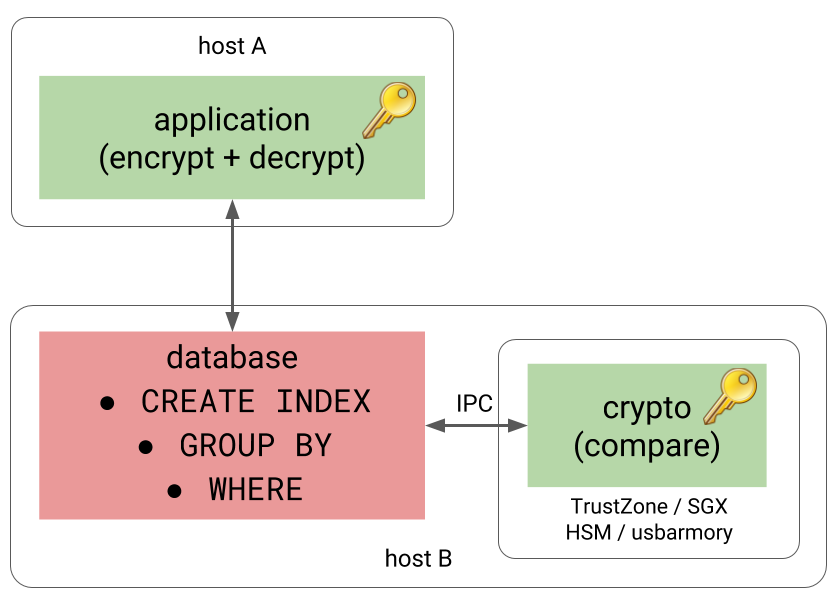
A more elaborate version of this would be running the process in a trusted execution environment, providing additional isolation. Pretty much every mainstream CPU vendor has a way to do this – Intel has SGX, AMD has SEV, ARM has TrustZone. The component might also run on a HSM or a device like usbarmory.
Each solution has a different set of pros / cons / limitations / performance characteristics, of course.
ccnumber
So, how could this be implemented on the database side, without messing with the database internals directly too much? Thankfully, PostgreSQL is extremely extensible and among other things it allows implementing custom data types. And that’s exactly what we need here. The experimental ccnumber extension implements a custom data type, offloading comparisons to component, either over TCP or IPC (using POSIX memory queues).
The encryption is done using libsodium (docs), a popular and easy-to-use library providing all the important pieces (authenticated encryption, keyed hashing).
Performance
Offloading operations to a separate component is certainly slower than evaluating them directly, but how much? The extension is merely a PoC and so there’s certainly room for improvement, but a benchmark may provide at least some rough estimates. The following chart shows how long it takes to build an index on ccnumber on a table with 22M rows.
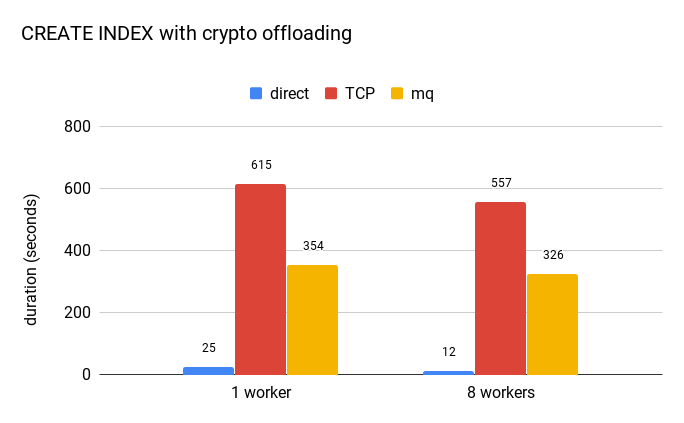
The blue bar represents an index created directly on the bytea value, representing the encrypted value. It’s clear the overhead is significant, creating the index is at least an order of magnitude slower (with TCP being twice slower than mq message queues). Furthermore, the custom data type can’t use sorting optimizations like abbreviated keys etc. (unlike the plain bytea type).
But this does not make this approach to encryption impractical. CREATE INDEX is very intensive in terms of number of comparisons, and you do it only very rarely in practice.
What probably matters much more is impact on inserts and lookups – and those operations actually do very few comparisons. It’s quite rare to see index with more than 5 or 6 levels, so you usually need very few comparisons to determine which leaf page to look at. And the other stuff (WAL logging, etc.) is not cheap either, so making the comparisons a bit more expensive won’t make a huge difference.
Moreover, an alternative to slightly more expensive index access is sending much more data to the application, and doing the filtering there.
The other observation is that increasing the number of workers does not speed CREATE INDEX significantly. The reason is that the parallel index build performs about 60% more comparisons compared to non-parallel one. And as those extra comparisons happen in the serial part of the algorithm, it limits the speedup (just like Amdahl’s law says).
Another way to look at this is how fast can the crypto component evaluate requests from the database, illustrated by the following chart:
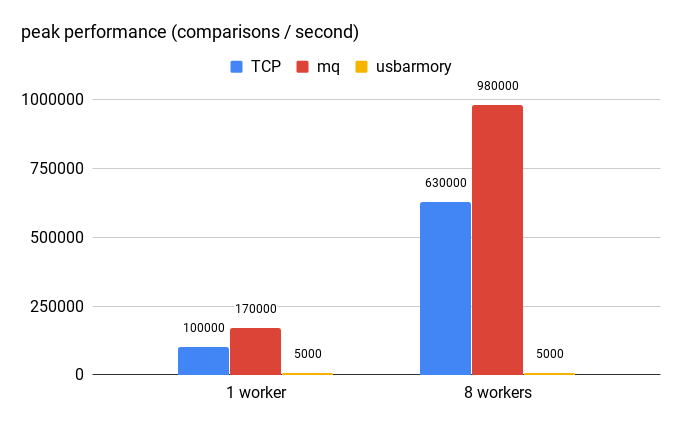
On this particular system (with Xeon E5-2620 v4 CPU, the TCP-based version handles up to 100k operations per second, and the MQ-based one handles about 170k. With 8 workers (matching the CREATE INDEX test) it can achieve about 630k / 1M ops.
For comparison, I’ve included also usbarmory, which is using a single-code NXP i.MX53 ARM® Cortex™-A8 CPU. Obviously, this CPU is much weaker compared to the Xeon, and handles only about 5000 operations per second. But it would still serve quite well as a custom HSM.
Summary
I hope this post demonstrates the offloading approach to encryption is viable, and solves the FDE and pgcrypto issues.
That is not to say the extension is complete or ready for production use, of course. One of the main missing pieces is key management – obtaining the keys, rotating then when needed, etc. The PoC extension has the keys hard-coded, but clearly that’s not a viable solution. Admittedly, key management is a very challenging topic on it’s own, but it also depends on how your application already does that – it seems natural to do it the same way here. I’d welcome feedback, suggestions or ideas how to approach this in a flexible manner.
You say “In the PostgreSQL world, people will typically recommend two solutions to this problem – pgcrypto.”, but that is only one solution. You also say “So neither pgcrypto is a viable solution to the problem at hand. “. I think you also mean FDE.
Damn, you’re right – there was a missing double quote in one of the <a> tags, so the FDE link was not visible. Fixed.
It seems to me that if comparisons are available against the decrypted data and the data is relatively constrained like credit card numbers, then someone exploiting a SQL injection could use the comparator to bisect the search space and find the exact number. Am I missing something about that?
Good question.
I don’t think the ability to inject SQL (or even running SQL directly on the database) allows you to bisect the data. Because to do that you’d need the ability to encrypt the values used for bisection, and ability to execute SQL does not give you that. That’s kinda the point of not having encryption keys in the database.
Of course, if you have a way to generate all possible CC numbers and encrypt them, then you could use these encrypted values. But well, there’s not much we can do about that. Once we provide the capability to compare values, it makes this issue kinda inevitable I’m afraid.
BTW, there’s a minor detail that I have not mentioned in the post. This scheme is not order-preserving, because the CC numbers are sorted by blake2b hash (using a key different from the encryption one). The primary goal was to reduce the number of remote comparisons, but it also means the ordering is different from simply ordering the plaintext values. I’m not entirely sure this is a good idea, as it might be seen as a side-channel, but it makes bisecting the data even more difficult.
Can you go into what the index looks like a bit more?
To me it seems the index is essentially going to contain hash(unencrypted cardnumber) and I’d have thought that would have some of the problems that you mention for storing SHA1 hashes of low entropy data (albeit not in a column that an SQL query could directly leak).
Also I notice you mention blake2 which is a fast hash. Have you put any consideration into using a slower hash (BCrypt etc) to make it more expensive to brute force an exposed index? Obviously that would impose a small cost during row creation, but maybe that is a valuable tradeoff?
You don’t have to build the index on a hash of the plaintext data – it can be built on the encrypted values directly. The database can navigate through it because it can offload the comparisons to the trusted component.
Now, the extension actually build the index on (short hash, encrypted value) and compares the short hash first. The idea is that this allows deciding most of the comparisons locally, without having to do the offloading. The hash can be very short (say, 1 or 2 bytes is enough) but it’s indeed an information leak. But this is not quite necessary – the index might be built on the encrypted data directly.
Regarding blake2b – the important feature is that it allows hashing with a secret key (see https://libsodium.gitbook.io/doc/hashing/generic_hashing) which you might imagine as using a secret salt. That’s what provides the security here, because the user can’t simply brute-force the mapping of card numbers to hashes (not to mention that 1 or 2 bytes would produce quite a few collisions anyway).
Using a slower hash is rather pointless here – it would somewhat contradict idea of speeding things up by eliminating many remote calls, i.e. it might be better to just get rid of the hashes entirely and offload everything.
“You don’t have to build the index on a hash of the plaintext data – it can be built on the encrypted values directly.”
I don’t think that’s what is happening though (the encrypted values are essentially random so you simply can’t build a useful index on the encrypted values).
I understand that the DB isn’t directly aware of the plaintext when creating the index, but if:
– the index structure is a product of comparator results
– the comparator results come from comparing plaintext values
then the index structure is is being built using the plaintext values.
I can’t get over the feeling that the index structure itself would then end up leaking information about the plaintext values (in a way that would presumably get worse as the number of entries increases).
In terms of brute forcing of the hash, I’m not sure a hash secret key adds much here, particularly for a fast hash. It is generally relatively easy to get a record with a known plaintext equivalent into a DB (just buy something!) and once you’ve done that, the faster the hash the cheaper it is to brute force the secret key. (Even if you only store a few bytes of hash the number of collisions probably aren’t really a defence for the hash secret key, as the collisions would drop away quickly with a few more known plain texts.)
If one of the risks you are defending against are “OS-level attacks (rogue sysadmin, someone gaining remote access to the box” then I think the concerns I’ve raised above all come into play in relation to the index structures this method would generate.
All of which isn’t to say that there’s nothing of value here, just that the devil is in the details with cryptography and careful consideration is needed of the risks and what is justified and permissible for your use case.
Credit cards are just about the most difficult thing to try and do anything interesting/clever with, they are so low entropy to begin with that it doesn’t take much to start leaking more information than is wise.
>> “You don’t have to build the index on a hash of the plaintext data – it can be built on the encrypted values directly.”
> I don’t think that’s what is happening though (the encrypted values are essentially random so you simply can’t build a useful index on the encrypted values).
Right, comparing the encrypted values directly would be useless. What I had in mind is building the index on encrypted data, but with comparisons offloaded to the trusted component (hence comparing the plaintext data).
> I understand that the DB isn’t directly aware of the plaintext when creating the index, but if:
> – the index structure is a product of comparator results
> – the comparator results come from comparing plaintext values
> then the index structure is is being built using the plaintext values.
>
> I can’t get over the feeling that the index structure itself would then end up leaking information about the plaintext values (in a way that would presumably get worse as the number of entries increases).
Right, I share this concern in general.
It’s essentially an information leak about ordering of the values, similar to what order-preserving encryption schemes have. What I’m saying is that if you don’t need to keep the ordering you can compare hash(key,data) which won’t leak anything about the ordering. You’ll still be able to decide if two encrypted values are equal or not (by calling the trusted component), but that’s about it. And you often don’t need a particular ordering – it’s enough that it’s consistent enough for lookups and grouping. Of course, if you need to support range queries that would not work, of course.
> In terms of brute forcing of the hash, I’m not sure a hash secret key adds much here, particularly for a fast hash. It is generally relatively easy to get a record with a known plaintext equivalent into a DB (just buy something!) and once you’ve done that, the faster the hash the cheaper it is to brute force the secret key. (Even if you only store a few bytes of hash the number of collisions probably aren’t really a defence for the hash secret key, as the collisions would drop away quickly with a few more known plain texts.)
Doesn’t that require the hash values to be known to the database? It’s true I’ve added a small piece of the hash to the stored value, but that’s not quite necessary – it’s an experimental optimization to eliminate some of the “remote calls” to the trusted component. But it would work even without that. So how do you bruteforce the hash (or the key) when you don’t know the hash values?
> If one of the risks you are defending against are “OS-level attacks (rogue sysadmin, someone gaining remote access to the box” then I think the concerns I’ve raised above all come into play in relation to the index structures this method would generate.
> All of which isn’t to say that there’s nothing of value here, just that the devil is in the details with cryptography and careful consideration is needed of the risks and what is justified and permissible for your use case.
> Credit cards are just about the most difficult thing to try and do anything interesting/clever with, they are so low entropy to begin with that it doesn’t take much to start leaking more information than is wise.
True. Thanks for the discussion.
Very interesting article, thank you for your share.
Just two things I have in mind:
– Do you know a use case where your need to use SQL operation on encrypted data? What I want to say is that we usually do not need to do this kind of stuff on them. If you do not need it, is not more secure to a specific database for very sensitive data?
– There is a important security vulnerability in the introduction of your article. You should NEVER store a hash of a sensitive value in a database without using salt and only with digest which are made to resist to bruteforce (eg bcrypt) + play x times.
1) In my experience it’s often the case that people would like to do more stuff with the data, but it’s not supported. Maybe not with card numbers, but certainly with other types of sensitive data.
2) Sure, the hashes have to be salted (and I should have mentioned it, but it seemed kinda natural). But the salts are kinda the problem with that scheme, because how are you going to compare the hashes? You’ll be able to say if a hash matches a particular card number, but how do you decide if two hashes (with different salts) are for the same card number? You can’t, which means you can’t build an index on those hashes etc.
I have the potential case where people would upload *financial* data, which would need to be processed and then uploaded to another provider.
I’d like those financial data to be encrypted in the database… and some how queryable while the user is logged in and have provided there password/private key to decrypt *their* data. I don’t even want the DBA nor SysAdmin to have access to the data unencrypted… the only place there would be a need to see the unencrypted data, is in the application and processing before POSTing to the registrar.
I’m still awaiting/looking for a solution in that case….
Great post and thanks for releasing the code, too! The discussions above were also very interesting.
The idea of comparison offload in an enclave is very similar to the “always encrypted with secure enclaves” feature of MS SQL server (released toward the end of 2018):
https://cloudblogs.microsoft.com/sqlserver/2018/12/17/confidential-computing-using-always-encrypted-with-secure-enclaves-in-sql-server-2019-preview/
https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/always-encrypted-enclaves?view=sql-server-ver15
The notes from their documentation on the design of indexing for encrypted columns is especially interesting:
https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/always-encrypted-enclaves?view=sql-server-ver15#indexes-on-enclave-enabled-columns-using-randomized-encryption
As for general security concerns, a nice review of security issues property revealing encryption schemes (includes order preserving) when applied to relational databases can be found here:
https://blog.acolyer.org/2017/06/16/why-your-encrypted-database-is-not-secure/